Canonicalization:正規化とは何か?どのように機能するか?

この記事は、ahrefs blog(ahrefs.com)に掲載された以下の記事を、ahrefsの許諾を得て日本語化したものです。
原文:Canonicalization: What It Is & How It Works
by May 19, 2022


Canonicalization: What It Is & How It Works
正規化(Canonicalization)とは、検索エンジンがあるページのメインバージョンを決定するために使用するプロセスであり、インデックスに登録され、ユーザーに表示されるページのことです。選択されたバージョンは正規化され、リンクなどのランキングシグナルはそのページに集約されます。このプロセスは、標準化(standardization、またはnormalization)と呼ばれることがあります。
GoogleウェブマスタートレンドアナリストのGary Illyes氏によると、インターネットの60%は重複コンテンツであるとのことです。
Google’s crawling process is highly focused on removing duplication because 60% of the internet is duplicate 🤯 @methode #seodaydk pic.twitter.com/OJ9OkP74DU
— Lily Ray 😏 (@lilyraynyc) March 30, 2022
正規化は複雑で、しばしば誤解されます。重複のほとんどは悪意があるとは思えません。ほとんどは技術的な問題が原因でしょう。これについてはもう少し詳しく見ていきましょう。
今回は、正規化プロセスの仕組みについて、以下のようにお話しします。
- 正規化のシグナル
- 正規化を確認する方法
- よくある間違い
正規化のシグナル
正規化プロセスでは、さまざまなシグナルが使用されます。そのなかには以下のようなものがあります。
- 重複コンテンツ
- 正規化されたリンク要素
- サイトマップのURL
- 内部リンク
- 外部リンク
- リダイレクト
- Hreflang
Googleは、すべてのシグナルを見て、それらを重み付けして、正規版を決定します。このバージョンは、インデックスされるページのバージョンであり、通常ユーザーに表示されるバージョンでもあります。
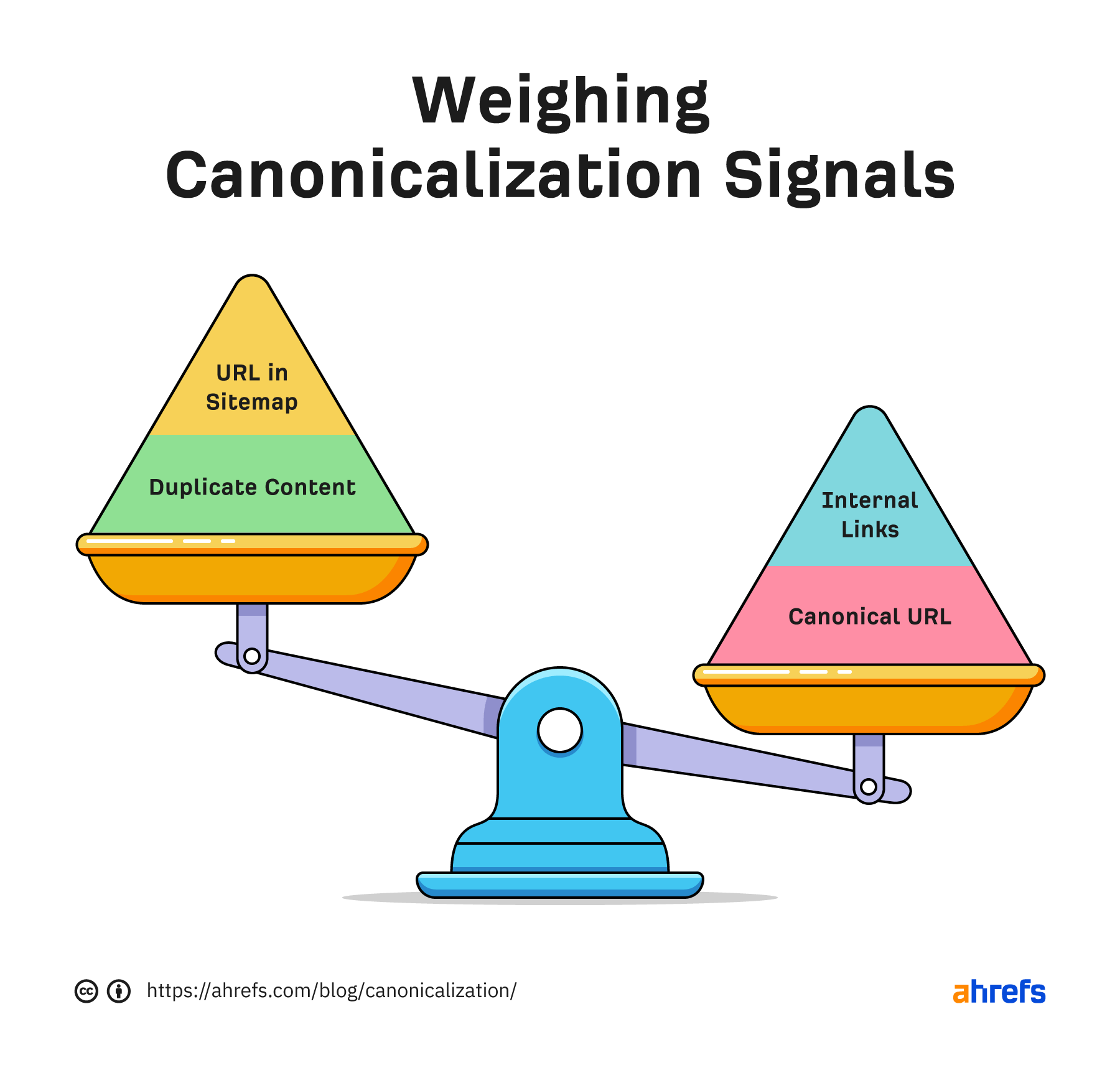
Googleが内部リンクとcanonical URLを元にcanonicalを決定する場合に考えられるシナリオ。
重複コンテンツ
重複コンテンツがある場合、Googleは正規版を選んでインデックスに登録します。対象となるすべてのページがページのクラスターを形成し、そのクラスター内のページに送られるシグナルは、選択された正規版に集約されます。この正規版は、時間の経過とともに変更される可能性もあります。
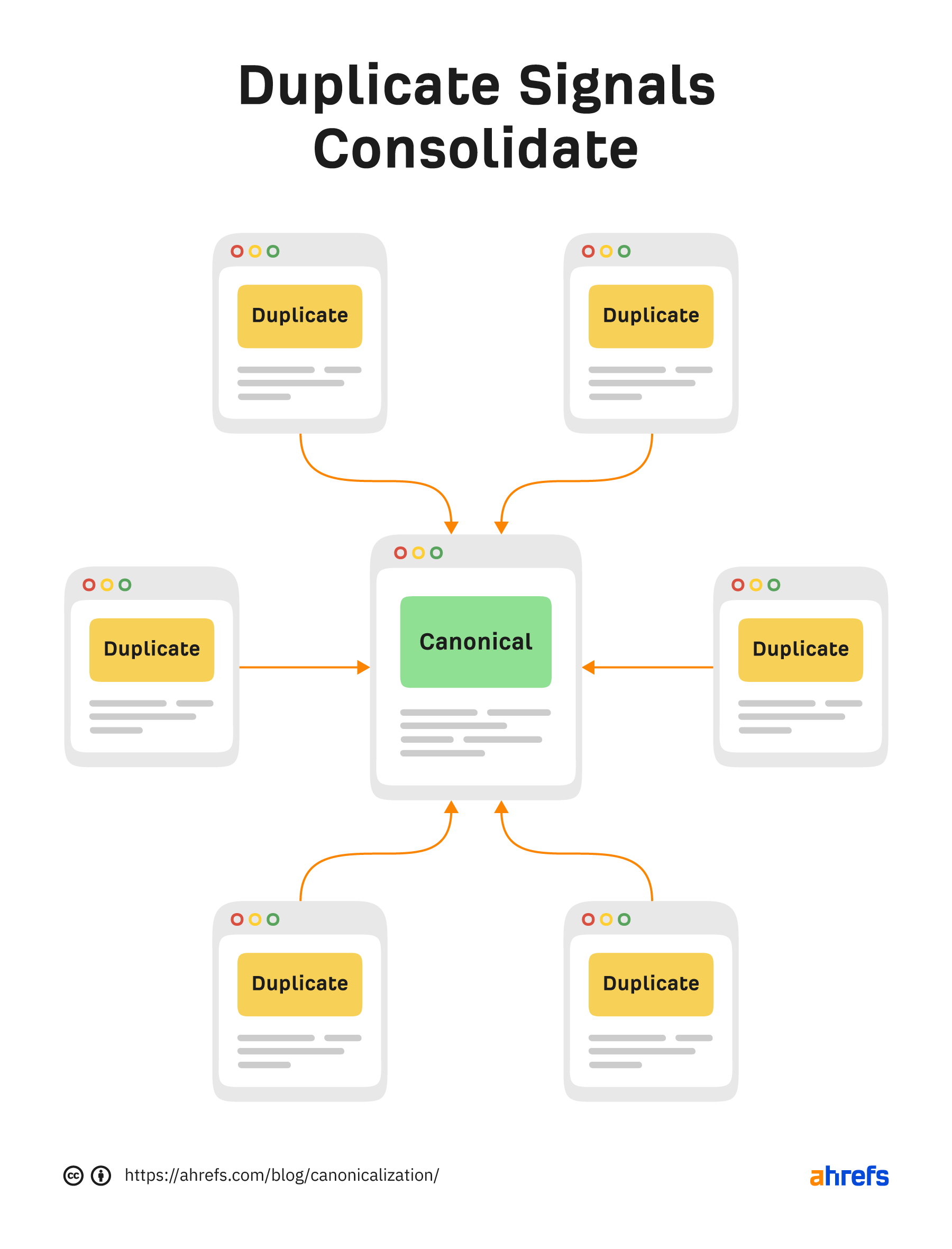
重複コンテンツのペナルティがあると信じているSEO業者がいるが、それは真実ではない。一般的には、どちらかのバージョンがインデックスされることになります。インデックスされたいバージョンではないかもしれませんが、同じページの他のバージョンと同じようにインデックスされ、順位も上がります。
以下は、重複ページや、時には正規化の問題を引き起こす可能性のあるものの例です。
- HTTP と HTTPS のバリエーション – 例: http://www.example.com と https://www.example.com
- 非wwwおよびwwwのバリエーション – 例: http://example.com と http://www.example.com
- URLの末尾にスラッシュがあるものとないもの – 例: https://example.com/page/ と https://example.com/page
- 大文字を含むURLと含まないURL – 例: https://example.com/page/ と https://example.com/Page/
- インデックスページなどのデフォルトバージョン – 例: https://www.example.com/, https://www.example.com/index.htm, https://www.example.com/index.html, https://www.example.com/index.php, https://www.example.com/default.htm など
- ページの代替バージョン – これには、モバイルバージョン(example.comおよびm.example.comなど)、AMPバージョン(example.com/pageおよびamp.example.com/pageなど)、印刷バージョン(example.com/page、example.com/page/print)、同じコンテンツを含む他の国向けの代替バージョン(example.com/en-us/, example.com/en-gb/, example.com/en-au/ など)、開発サイトまたはステージングサイトのバージョン(example.com/ dev など)などがあります。
- URLパラメータ – 例:example.com?parameter=whatever. これらは、トラッキングコード、ファセット・ナビゲーション、コンテンツの並べ替え、セッションIDなどのために存在する場合があります。パラメータによってページのコンテンツが変更され、重複しないようになる場合もあります。
- 他のページがコンテンツを完全に表示している場合 – 他のページがコンテンツを完全に表示している場合、Googleは間違ったcanonicalを選択する可能性があります。これには、ブログのメインページ、ページ分割されたページ、タグページ、カテゴリーページ、フィードページなどが考えられます。
- スクレイピングされたコンテンツやシンジケートされたコンテンツ – コンテンツ・シンジケーションのベストプラクティスは、一般的に、オリジナルのコンテンツに戻るcanonicalタグを持つか、少なくともオリジナルのコンテンツにリンクすることを推奨しています。それは、canonicalに選ばれたものが、全く別のドメインである可能性があるからです。canonicalとしてオリジナルのソースを選ぼうとしますが、場合によっては間違ったページを選んでしまうこともあります。
これらのほとんどの場合、通常問題ではありません。前述したように、Googleは通常、あるバージョンか別のバージョンを正規のものとして選択します。これには、いくつかの例外があります。
1.コンテンツ・シンジケーション(コンテンツ配信)では、オリジナルのソースが正規のものとして選択されないことがあります。これは本当に問題です。もし、あなたが書いた記事を他の誰かがランキングし始めたら、どう感じるでしょうか?
2.Hreflangは、国際的なサイトでの重複を解決するものではありません。Googleは一般的に、正しいバージョンを表示するようにすり替えようとします。しかし、それは保証されたものではなく、この設定はしばしば弾かれます。そうなると、ユーザーは間違った国のページを見ることになります。国際的なサイトでは、同じコンテンツを複数のページで表示することは避けたほうがよいでしょう。
3.一部のJavaScriptサイト(通常はアプリのシェルモデル)では、ページの初期コードが他のページや他のウェブサイトのコードのように見えることがあります。これらのページは、同じWebサイト、あるいは異なるWebサイトの他のページに正規化されることがあります。
hreflangとJavaScriptのコンテンツに関する問題の一部は、Googleが重複パターンを検出するクロールアルゴリズムを介して、コードを見た後に、さらにページをレンダリングした後に、重複検出を実行している可能性があることだと私は考えています。
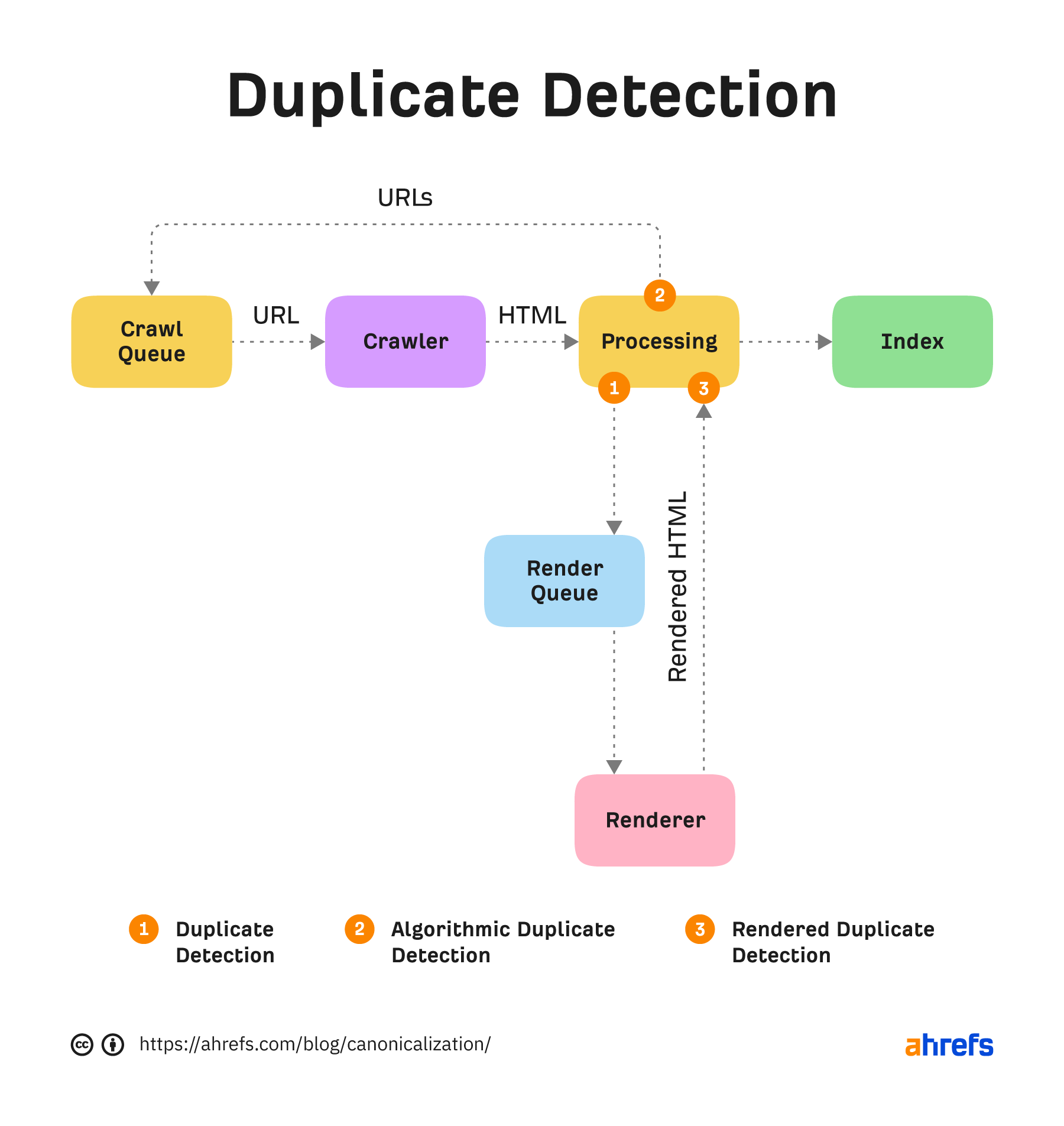
Googleのレンダーパスは、重複検出システムが稼働していると思われる箇所をマークアップしています。
hreflangを使用しているページでは、クロールせずに重複と判断した場合、適切に入れ替えができない可能性があります。
ページがレンダリングされる前に、HTMLの内容から別のページのように「見える」可能性があるのです。Googleはこの初期バージョンに基づいてcanonicalを選択し、すでに重複ページと判断しているため、レンダリングの優先順位をつけないことがあります。これは通常、レンダリング後に解決されますが、解決までに時間がかかることもあります。
Googleは、重複ページの正規化に関して、一般的に準拠するいくつかのルールを定めています。
1. HTTPのページよりもHTTPSのページを優先する。
Googleは通常、HTTPS版をインデックスに登録しますが、以下のような問題や矛盾する信号があると、代わりにHTTP版を選択する場合があります。
- 無効なセキュリティ証明書を持っている。
- HTTPSページがページ内のHTTPリソースにリンクしている(画像は除く)。
- HTTPSがHTTPにリダイレクトされる。
- HTTPS ページに、HTTP ページを指す rel=”canonical” リンク要素がある。
2. 長いURLより短いURLの方が好まれる。
これは、長年にわたってSEO関係者によって、すべてのURLを短くするべきだという誤解を招いてきました。しかし、これは本来の意味とは異なります。Googleが言ったのは、例えば、きれいな短いURLと、パラメータが付いた長いURLがあった場合、一般的には、パラメータの付いていない短いURLを正規のバージョンとして選択する、ということなのです。
canonical link 要素
これは一般的にcanonicalタグとも呼ばれます。以下のようになります。
canonicalタグは、正規化シグナルの1つに過ぎないため、ヒントと呼ばれることがあります。Googleは、他のシグナルの方が強力な場合、このタグを無視します。
canonicalタグが利用されていれば、リンクなどのシグナルはすべて通過します。しかし、canonicalが無視された場合、何の価値も渡されません。値は失われず、元のページに残るか、Googleがcanonicalとして選択したページに移動します。
canonical link要素は、2通りの方法で実装することができます。<head> セクションに記述する方法と、HTTP ヘッダーに記述する方法です。
面白い逸話があります。GoogleのSEOスターターガイドは、以前はPDFでした。HTTPヘッダーにcanonicalタグが設定されていなかったので、人々は自分たちの複製バージョンでリストを「盗む」ことがよくあったそうです。
ページの<head>セクションが、本来あるべき位置より前に終了してしまうことがあります。これは通常、<head>内のタグが適切に閉じられていないことが原因です。このような場合、<body>セクションにcanonicalタグが代入されることがあります。このような場合、canonicalタグは利用されません。

<body>セクションにあるcanonicalタグは無効です。
サイトマップのURL
サイトマップに含めるURLは、正規化シグナルでもあります。ほとんどの場合、インデックスさせたいページのURLのみを含めるようにしてください。
サイトマップのURLはクロールにも役立つので、例外もあります。ウェブサイトの移行後は、正規化されていなくても、古いページをリストアップするサイトマップを作成する必要があります。そうすることで、リダイレクトの処理が速くなります。このサイトマップは、ほとんどのリダイレクトがピックアップされ、処理された後に削除することをお勧めします。
内部リンク
ページへのリンクの張り方は重要です。内部リンクも正規化シグナルのひとつです。
一般に、正規化したいページのバージョンにリンクし、変更された可能性のあるURLへのリンクを更新する必要があります。ただし、ファセット・ナビゲーションなど、例外もあります。このような場合、ユーザーにとって最適なことが、SEOにとって最適なことに優先することがあります。
外部リンク
あなたのページに他の人がどのようにリンクしているかは重要です。外部リンクが最新版を指すように更新されていれば、最新版のページがインデックスされることを望んでいることを示すのに役立ちます。
リダイレクト
リダイレクトにはいくつかの種類があり、それらはすべて正規化シグナルです。これらはPageRankを渡し、どのURLがGoogleのインデックスに表示されるかを決定するのに役立ちます。
301のような恒久的なリダイレクトは、新しいURLにシグナルを転送します。302や一部の307のような一時的なリダイレクトは、リダイレクト前のURLにシグナルを送ります。一時的なリダイレクトが十分な時間放置されているか、リダイレクト先のURLがすでに存在している場合、永久的なリダイレクトとして扱われ、代わりにシグナルが新しいURLに送信されることがあります。この正規化シグナルについては反転させるのに十分なシグナルが必要です。リンクが蓄積され、内部リンクが変更され、サイトマップのURLが更新されるなどすると、古いURLよりも新しいURLを指すシグナルが多くなり、反転が発生します。
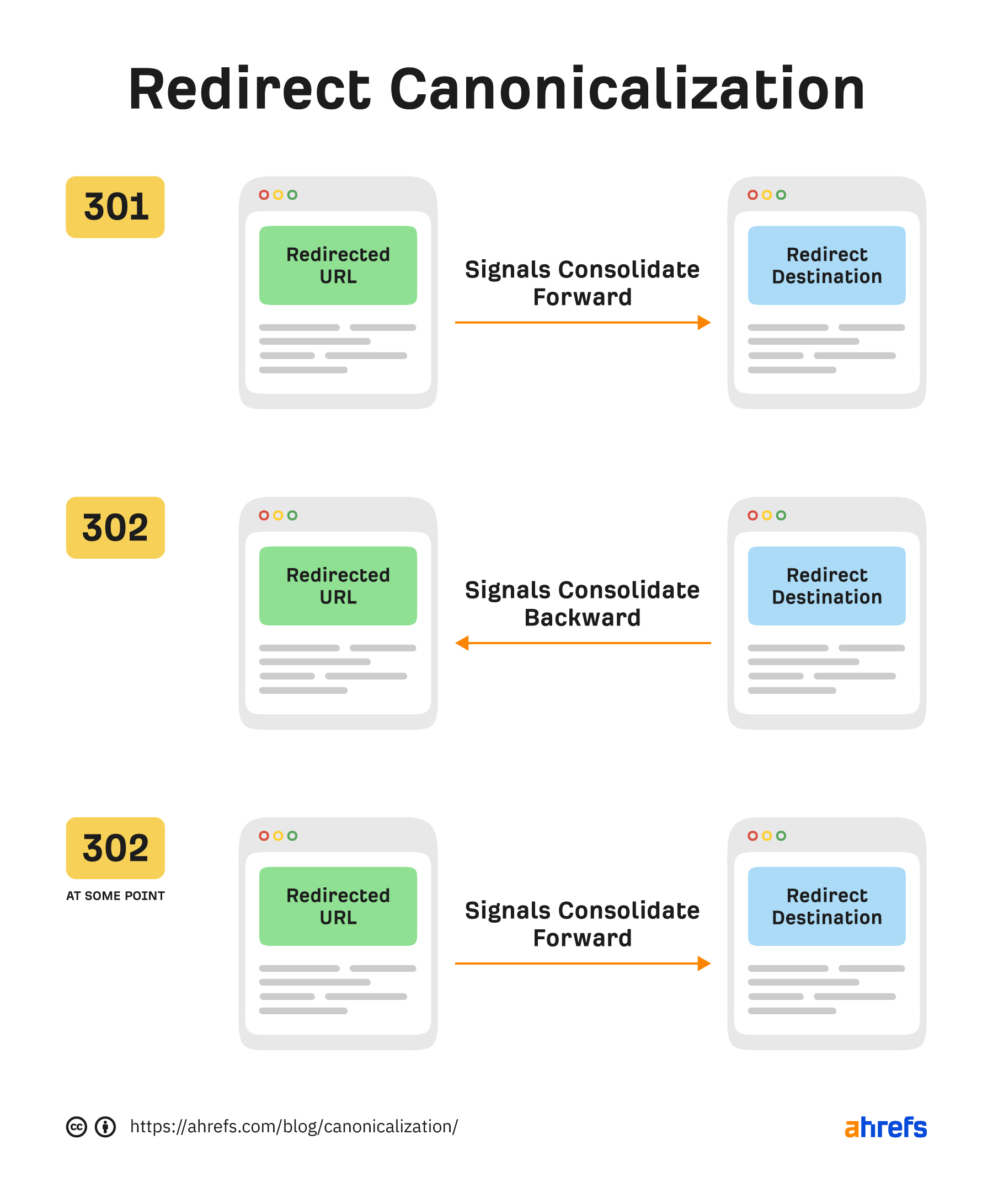 ある時点で、302のような一時的なリダイレクトについては、規模が逆転します。
ある時点で、302のような一時的なリダイレクトについては、規模が逆転します。
307には2種類のケースがあります。一時的なリダイレクトであるケースでは、302と同じように扱われ、転送前のURLに統合しようとする。ウェブサーバがクライアントにHTTPS接続のみを使用するよう要求している場合(HSTSポリシー)、ブラウザにキャッシュされているため、Googleは307を見ません。最初のヒット(キャッシュなし)は、サーバーのレスポンスコードが301か302である可能性が高いです。しかし、それ以降のリクエストでは、ブラウザに307が表示されます。
恒久的なリダイレクトの種類
- HTTP 301
- HTTP 308
- Meta refresh 0
- HTTP refresh 0
- JavaScript location
- Crypto redirect
一時的なリダイレクトの種類
- HTTP 302
- HTTP 303
- HTTP 307 (サーバ側、ブラウザのキャッシュではない)
- Meta refresh >0
- HTTP refresh >0
シグナルの統合
シグナルは通常1年後に永久に統合されます。この期間後にリダイレクトが削除された場合、シグナルはリダイレクトされたページに留まります。元のページが復元された場合、新しいシグナルは復元されたページに送られますが、古いシグナルはリダイレクト先のページに統合されたままです。
Hreflang
Hreflangも正規化するためのシグナルです。この部分は複雑なので、Hreflang(初心者のための簡単なガイド)を読むことをお勧めします。
正規化を確認する方法
Googleがcanonicalとして選んだものを知るには、Google Search ConsoleのURL検査ツールが主な情報源となります。URLを入力すると、宣言されたcanonicalが何であるか、そしてGoogleがcanonicalとして選んだものが表示されます。
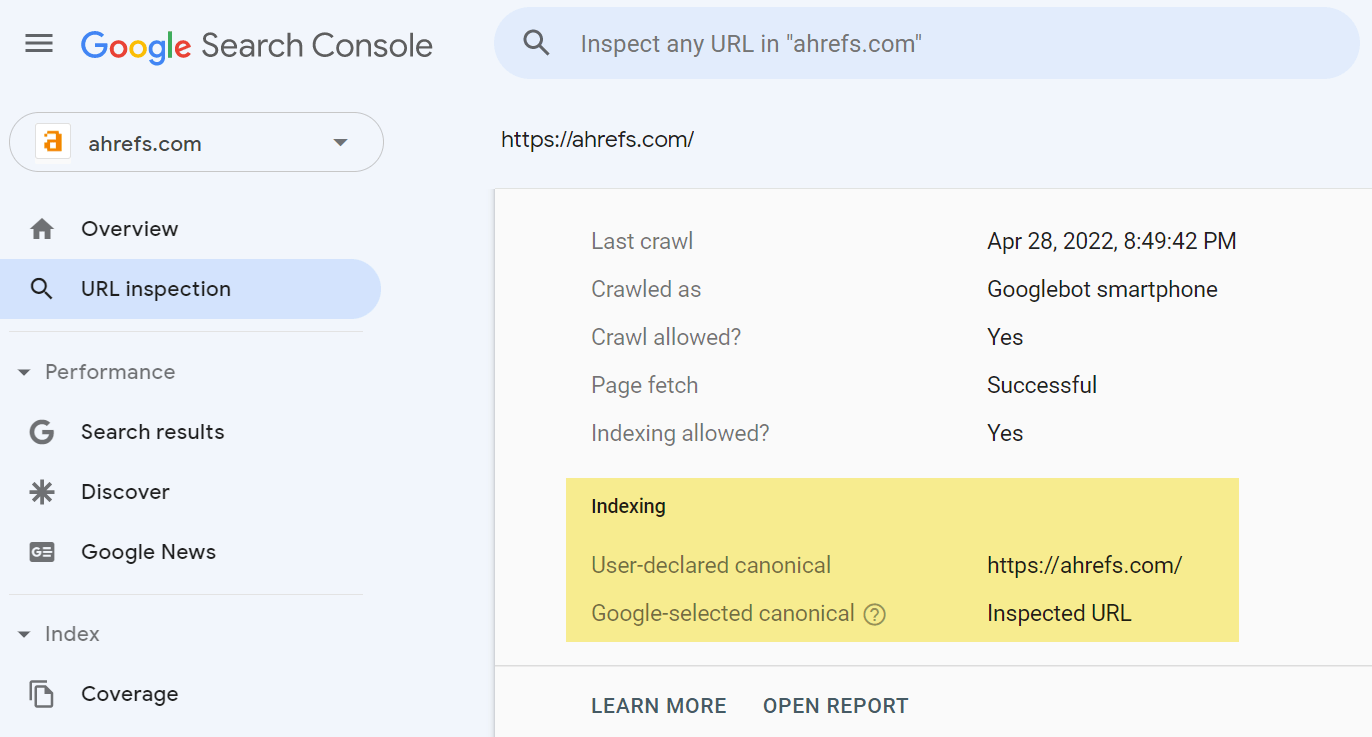
Google Search Consoleにアクセスできない場合、Googleがインデックスしているページのバージョンを確認する推奨方法は、GoogleにURLを貼り付けることです。一番上の結果は、通常、canonicalです。
同様に、Googleでページのキャッシュバージョンを確認し、異なるページが表示された場合、Googleはそのページの異なるバージョンを選択したことになります。
注意:canonicalを確認するためにsite:検索を使わないでください。Googleが知っているものを表示し、必ずしもインデックスされているものや選択されたcanonicalを表示するわけではありません。
AhrefsのSite Auditのなかで、正規化に関する多くの問題がわかります。ほとんどの場合、ベストプラクティスにフラグを立てていることに留意してください。canonicalはヒントであるため、Googleやその他の検索エンジンは、どのバージョンのページをインデックスするか選択する必要があります。
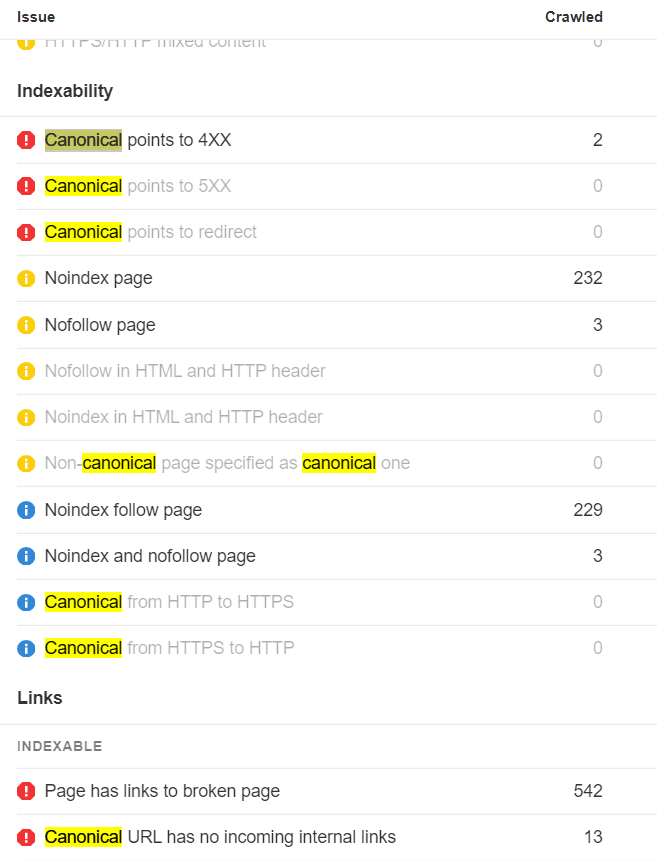
あなたのウェブサイトに正規化に関する問題がたくさんあったとしても、検索エンジンは、どのバージョンをインデックスすべきか、どこにシグナルを集約すべきかを把握することができるかもしれません。彼らにとっては、実質的な問題は生じないかもしれません。
面白い事実があります。サイト監査を行う際、クロールクレジットとしてカウントするのは、正規化されたバージョンのページのみです。他のツールでは、ページの全バージョンをクレジットにカウントするものもあります。多くのサイトでは、1ページあたり複数のクレジットを消費することになります。
よくある間違い
正規化で失敗することはたくさんあります。よくある間違いをいくつか見てみましょう。
間違い1:robots.txtで正規化したURLをブロックする
robots.txtでURLをブロックすると、GoogleはそのURLをクロールできなくなり、そのページのcanonicalタグを見ることができなくなります。つまり、正規化されていないページから正規化されたページへの「リンクエクイティ」の移転ができなくなるのです。
クロールバジェットの問題がない限り、おそらくすべてのシグナルを統合させる方がよいでしょう。いくつかのバージョンをブロックまたはnoindexにするとしても、代わりにcanonical化すべきリンクがあるバージョンをチェックするのもよいでしょう。しかし、Googleは時間の経過とともに正規化されていないページをクロールしなくなる傾向があるため、そのまま待つ方がよいかもしれません。
間違い2:正規化したURLを “noindex “に設定する
決してnoindexとrel=canonicalを混同してはいけません。両者は矛盾する指示です。
ジョン・ミューラー氏が述べるように、Googleは通常、「noindex」タグよりもcanonicalタグを優先します。
間違い3:正規化されたURLに4XXのHTTPステータスコードを設定する
canonical化されたURLに4XX HTTPステータスコードを設定すると、「noindex」タグを使用するのと同じ効果があります。Googleはcanonicalタグを見ることができず、canonicalバージョンに「リンクエクイティ」を転送することができなくなります。
間違い4:ページ番号のついたページすべてを最初のページに正規化する
ページ分割されたページは、そのシリーズで最初にページ分割されたページに対して正規化されるべきではありません。その代わりに、自己参照型の正規化をすべてのページで使用すべきです。
なぜでしょうか?JohnがRedditで述べているように、これはrel=canonicalの不適切な使用です。
この投稿は正規化についてなので、避けるべき主なことは、ページ1を指すページ2でrel=canonicalを使用することです。ページ2はページ1と同等ではないので、そのようなrel=canonicalは不正確です。
 ジョン・ミューラー、ウェブマスタートレンドアナリスト Google
ジョン・ミューラー、ウェブマスタートレンドアナリスト Google
SEOのためのページネーションとベストプラクティスに関するガイドを用意していますので、ご興味があればご覧ください。
間違い5:Google Search ConsoleのURL削除ツールを使って正規化を行う。
これは、URLのすべてのバージョンを削除し、効率的に検索結果からインデックスを削除することになってしまいます。
間違い6:正規化シグナルの一貫性を保てない
先ほどお話したように、正規化シグナルにはさまざまなものがあります。
異なるシグナルが異なる正規化を提案するということは、Googleに正規化の選択を委ねることになります。Googleに表示するシグナルに一貫性があればあるほど、そのバージョンがcanonicalとして選択される可能性が高くなります。
間違い7:hreflangと一緒にcanonicalタグを使用しない
hreflangタグは、ウェブページの言語と地理的なターゲットを指定するものです。
Googleは、hreflangを使用する場合、”同じ言語のcanonicalページを指定するか、同じ言語のcanonicalが存在しない場合は、可能な限り最適な代替言語を指定する “べきであると述べています。
間違い8:複数のrel=canonicalタグを指定する
複数のrel=canonicalタグがあると、通常、Googleはそれらを無視します。多くの場合、CMS、テーマ、プラグインなど、異なるポイントでタグが挿入されるため、このような現象が起こります。このため、多くのプラグインには、canonicalタグのソースが自分だけであることを確認するための上書きオプションが用意されています。
また、JavaScriptで追加されたcanonicalも問題となる場合があります。HTMLレスポンスにcanonical URLが指定されていない場合、JavaScriptでrel=canonicalタグを追加すると、Googleがページを表示する際にそれが利用されるはずです。しかし、HTMLでcanonicalを指定し、JavaScriptで優先順位を入れ替えた場合、Googleに複雑なシグナルを送ることになります。
間違い9:<body>内にrel=canonicalを記述する
rel=canonicalは、文書の<head>内にのみ記述する必要があります。<body>セクションに記述されたcanonicalタグは無視されます。
これが問題になるのは、文書の解析の場合です。ページのソースコードの正しい位置にrel=canonicalタグがあっても、閉じていないタグ、JavaScriptの挿入、<head>セクションの<iframe>など、さまざまな原因でレンダリング中に<head>が早期に終了してしまうことがあるのです。このような場合、canonicalタグはレンダリングされるページの<body>に誤って投げ込まれ、そこで尊重されないことがあります。
まとめ
Google Search ConsoleのURLパラメータツールや優先ドメイン設定など、SEOが正規化を扱うために持っていたツールの多くは取り払われました。しかし、Googleがcanonicalを選択するのに役立つ他のシグナルはまだたくさんあります。
質問がある場合は、Twitterでメッセージしてください。
この記事は、ahrefs blog(ahrefs.com)に掲載された以下の記事を、ahrefsの許諾を得て日本語化したものです。
原文:Canonicalization: What It Is & How It Works
by May 19, 2022
この記事の筆者: