
Wayback Machineの使い方とは?見られない原因や活用方法も解説

Wayback Machine(ウェイバックマシン)は、過去のWebページを閲覧できるツールとして知られていますが、「具体的にどう使うのか分からない」「見れない場合の原因が知りたい」と感じている方も多いのではないでしょうか。
実際に、サイトの更新や削除によって過去の情報が確認できなくなるケースは少なくありません。そのような場面で、過去のページを遡って確認できるWayback Machineは、情報収集や分析の手段として活用されています。
また、SEO対策においても、競合サイトの変遷や自社サイトの過去データを把握することで、改善のヒントを得ることが可能です。
この記事では、Wayback Machineの基本的な使い方から、見れない場合の原因、活用方法までを整理しながら、実務で使える形で分かりやすく解説します。


Wayback Machineとは何ができるツール?

Wayback Machine(ウェイバックマシン) は、過去のWebページを保存・閲覧できるアーカイブツールです。特定のURLを入力することで、そのページが過去にどのような状態だったのかを時系列で確認できます。たとえば、削除されたページの内容を確認したり、サイトのデザインや構成の変化を比較したりすることが可能です。このような特徴から、単なる閲覧ツールとしてだけでなく、SEO分析や競合調査にも活用されています。
Wayback Machineが見られない原因
Wayback Machineを使っても、すべてのページが閲覧できるわけではありません。場合によっては、過去ページが表示されないケースもあります。主な原因としては、対象ページがアーカイブされていない場合や、robots.txtの設定によってクロールが制限されているケースが挙げられます。
また、サイト側の設定や削除依頼によって、過去データが非公開になっていることもあります。閲覧できない場合は、別の日時を選択したり、代替ツールを併用したりすることで確認できる可能性があります。
Wayback Machineの使い方
Wayback Machineの使い方は大きく4つあります。
- URLで検索する
- キーワードで検索する
- 画像、音楽、動画などを検索する
極めて膨大な数のデータが保管されておりますので、探したいものを見つける手法を使うべきですが、特に利用されるのがURLで過去のサイトを検索し、過去の履歴を閲覧する手法です。
URLから検索する
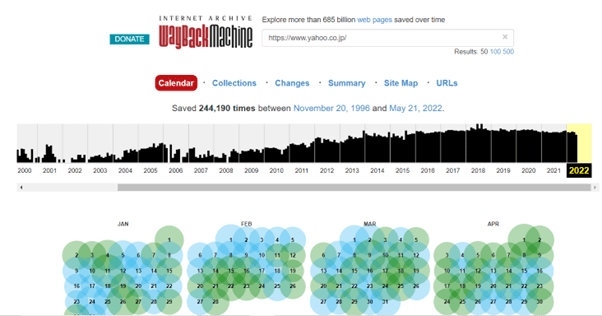
上図は「https://www.yahoo.co.jp/」と入力し検索した結果です。
さすがに大規模サイトなだけあって、1996年から2022年の間に244,190回も保管されています。年表を見てもカレンダーを見ても相当数の保管回数があることがわかります。
上の事例ではトップページのURLを入力しましたが、特定のページの過去分を見たい場合には確認したい記事のURLを入力しても構いません。
年表をクリックすると該当年のカレンダーを閲覧できますし、カレンダーからは何月何日の何時に保管されたデータをみたいのかを選択できます。(下図参照)

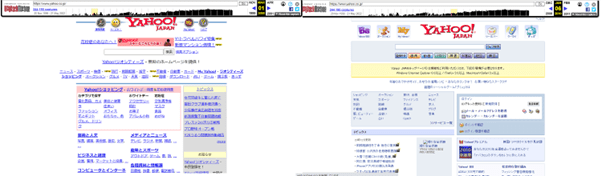
例えば、下図の左は2000年のYahoo!JAPANのトップ、右は2010年のYahoo!JAPANのトップです。基本機能は変わっていないものの、デザインは現在のものとずいぶんと変化していることがわかります。
なお、Yahoo!JAPANは大規模なサイトであるため、保存回数が非常に多いものの、サイト規模が小さいサイトの場合には下図のように月に1回~2回程度しか保存されないこともよくあります。
世界的に大量のデータを保管しているとはいえ、必ずしも過去データが閲覧できるというわけではございません。
キーワードから検索する
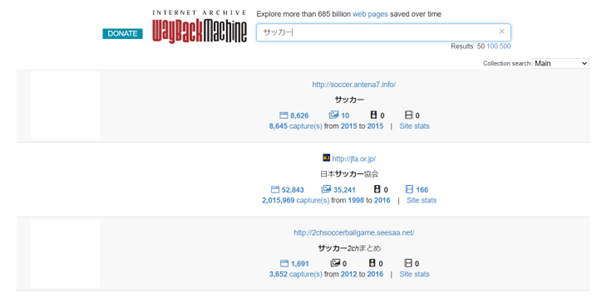
Wayback Machineではキーワード検索をすることも可能です。検索窓にキーワードを入力するだけですので簡単に調べることができますが、検索結果は上図(サッカーで検索した例)のように普段見ている検索結果とは違い違和感があるかもしれません。
Wayback MachineはURLで検索することが多いため、補助的な機能として使うとよいです。
画像・本・動画コンテンツ検索
ページの最上部、ロゴの右側にはさまざまなアイコンが並んでいます。通常はURL検索、次いでキーワード検索をすることで過去データを閲覧できますが、書籍、画像、音楽など一般的なサイト以外のデータを確認することも可能です。
Wayback Machineにページを保存する方法
Wayback Machineは非常に優秀なサイトですので、世界中のWEBサイトを自動でアーカイブします。しかし、アーカイブするリソースは限られているため新規サイトでは保管されなかったり、保管されるとしても頻度が非常に少ないということは十分にありえます。
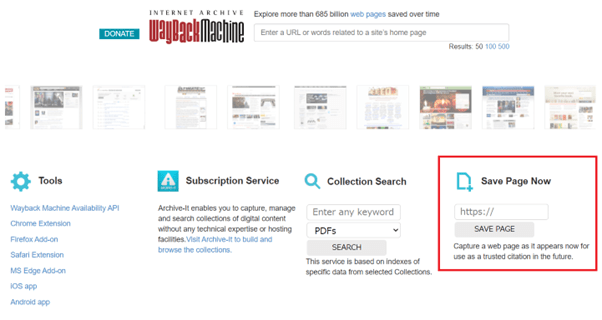
そこで、Wayback MachineのTOPページ右下(上図赤枠)にあるSave Page Nowに保存したいページのURLを入力して保存することが可能です。
入力窓の下には「Capture a web page as it appears now for use as a trusted citation in the future.(将来信頼できる引用として使用するために、現在表示されているWEBページをキャプチャしてください。)」とあるように、ページを保存することは将来、誰かのためになるかもしれません。
Wayback Machineに保存されたページの削除方法
Wayback Machineに保存されているページの削除について、ヘルプページには以下のように記載があります。
How can I exclude or remove my site’s pages from the Wayback Machine?
You can send an email request for us to review to info@archive.org with the URL (web address) in the text of your message.
つまり、具体的な削除依頼フォームがあるわけではなく、info@archive.org宛てに削除してほしい旨の本文と共に削除してほしいURLを記載する必要があります。
ただし、運営元のInternet Archiveはアメリカの団体ですので、メールのやり取りはすべて英文でおこなうため、やり取りには注意が必要です。
Wayback Machineに保存されないようにする方法
Wayback Machineは非常に便利なツールであり、自動保存してくれるため通常は閲覧をするだけが利用用途になるはずです。
しかし、削除するとなると削除してほしいURLをメールで送り、英語でやり取りする必要があり手間がかかります。そのため、もしアーカイブしてほしくないと思った場合には事前にアーカイブされないような策を講じる必要があります。
ただし、アーカイブされないようにするためにはrobots.txtを書き換える必要があり、設定を間違えるとGoogleのような検索エンジンのアクセスも拒否することになるため、SEO的に大きなマイナスの影響を受ける可能性があります。
通常はWayback Machineにアーカイブされても悪影響はありませんので、どうしても必要な場合に限り、robots.txtの知見がある人に設定を依頼するようにしてください。
robots.txtとは
robots.txt(ロボッツテキスト)とは、検索エンジンのようなクローラーに対して、サイトのどの部分にアクセスを許可するか、拒否するのかを設定できるファイルです。
検索エンジンの検索結果に表示されないようにするためにrobots.txtの利用を考えている人もいますが、通常は検索結果に表示されないためにはnoindex設定を利用したり、パスワード設定をすべきです。
アクセスを制限する方法
robots.txtを書き換えることにより、Wayback Machineのクローラーをサイトにアクセスさせないようにすればアーカイブされることはなくなります。
構文そのものは非常に簡単で、次の2行を追記するだけでアーカイブされません。
User-agent: ia_archiver
Disallow: /
ただし、上記の設定ではサイトのすべてのアーカイブを拒否する設定になっています。特定の一部のディレクトリだけを拒否する場合には次のように記載してください。
User-agent: ia_archiver
Disallow: /sample-directory/
もし特定のページだけのアーカイブを防ぎたい場合には次のようにさらに指定してください。
User-agent: ia_archiver
Disallow: /sample-directory/sample-file/
繰り返しますが、robots.txtは設定を間違えるとSEOにマイナスの影響を及ぼしますので、必ず設定方法のわかる方が対応するようにしてください。
Wayback Machineを使うメリット
Wayback Machineを活用することで、過去のWebページを確認できるだけでなく、サイト運用やSEO分析にも役立てることができます。
たとえば、競合サイトの過去のコンテンツや構成を確認することで、どのような変更が行われたのかを把握できます。また、自社サイトの過去ページと比較することで、改善の方向性を整理することも可能です。
このように、Wayback Machineは単なる閲覧ツールではなく、Webマーケティングの分析にも活用できる点が特徴です。
Wayback Machineの活用方法
Wayback Machineは過去のWEBデータを見るためのサイトですが、さまざまな活用方法があります。
代表的なものがSEO対策(競合分析)と中古ドメインのチェックです。拡張機能もあるため、効果的に利用して自社サイトの改善に活かしてください。
拡張機能
Wayback Machineには以下のようなAPIやアドオンが用意されています。
- Wayback Machine Availability API
- Chrome Extension
- Firefox Add-on
- Safari Extension
- MS Edge Add-on
- iOS app
- Android app
頻繁に利用する場合にはアドオンは特に利用される機能です。
SEO対策(競合分析)
Wayback Machineは過去のWEBサイトを閲覧することができます。これは、競合サイトや自社サイトの変化の推移をみて、検索順位と照らし合わせることで過去にどのようなサイトがどこをどのように変えて順位が上昇または下降したのかを見ることができるということです。
特に競合サイトが大きく変化をした場合には具体的にどこを変更したのかを見ることで変更の意図を考え、自社の改善に活かすことができないかを検討できるため非常に便利です。
中古ドメインの過去データを確認
中古ドメインを購入する場合、そのドメインが過去にどのような変遷を辿ってきたのかは重要です。過去のサイトテーマによっては想定外の外部リンクがついていたり、スパムサイトとして利用されていたという理由でGoogleからペナルティを受けてしまったりする可能性があるためです。
ペナルティを受けているかどうかはドメインを購入し、Googleサーチコンソールに登録するまでわかりませんが、事前にどのようなサイト運営をされてきたのかを確認することはWayback Machineを利用することでドメイン購入前にできます。
削除されたページの閲覧
Wayback Machineではその特性上、現存するサイトやページの過去の状況だけではなく、既に削除されてしまったサイトや記事も閲覧することができます。
ただし、現在残っていないサイトということは公開期間が短い可能性があり、必ずしもアーカイブされているとは限りません。あくまで参考程度に閲覧できるかもしれないとお考え下さい。
Wayback Machineの代替ツール
WEBアーカイブ確認ツールとしてはWayback Machineがもっとも有名ですが、Wayback Machineでは確認できない場合もあります。そのような場合には次のような代替ツールを利用してください。
ウェブ魚拓
ウェブ魚拓 はWayback MachineのようにWEBサイトをアーカイブするサイトです。最大の違いはWayback Machineはクローラーが自動的にWEBサイトを登録していくのに対し、ウェブ魚拓は利用者がURLを入力して保存する点です。
しかし、画像データやFLASHなどもほぼ完全に保管できるため、再現性が高い点は優れています。
Stillio
Stillio は自動スクリーンショットサービスです。 一定間隔で頻繁にWebサイトのスクリーンショットをキャプチャすることができます。
archive.today
archive.today もWEBアーカイブツールです。ドメインの画像も保存する点が特徴的ですが、Wayback Machineの補助として利用できる程度です。
PageFreezer
PageFreezer もWayback Machineの代替ツールとして有名です。こちらも自動化されていますが、有料な点がWayback Machineと大きく異なります。
タイムトラベル

TimeTravel はアーカイブしているサイトを検索することができる点で非常にユニークです。同じドメインであってもアーカイブしているサイトによって見え方が異なるため、違う切り口で情報が欲しい際に役立つかもしれません。
まとめ
 Wayback Machineは、過去のWebページを確認できるツールとしてだけでなく、競合分析やサイト改善のヒントを得るためにも活用できます。特に、過去と現在のページを比較することで、どのような変更が行われてきたのかを把握しやすくなります。こうした情報は、自社サイトの方向性を見直す際にも参考になります。
Wayback Machineは、過去のWebページを確認できるツールとしてだけでなく、競合分析やサイト改善のヒントを得るためにも活用できます。特に、過去と現在のページを比較することで、どのような変更が行われてきたのかを把握しやすくなります。こうした情報は、自社サイトの方向性を見直す際にも参考になります。
一方で、すべてのページが閲覧できるわけではなく、設定や保存状況によって確認できない場合もあるため、必要に応じて他のツールも併用することが重要です。用途に応じて使い分けながら、効果的に活用していきましょう。

SEOとWEBマーケティングの東京SEOメーカーTOPへ戻る
この記事の監修者

新潟大学大学院を卒業後、事業会社で10年働く間にSEOに出会う。自身でサイトを多数立ち上げ、実験と検証を繰り返しながらSEOを研究。お金に変えることを目的とはせず、ユーザーに何が有益かを問い続け改良を繰り返すうち、「インターネット上の真実ではない情報を正してユーザーのためになる情報を発信する」という天啓を得る。現在は東京SEOメーカーの上級SEOアドバイザーとしてアサイン。



















