
インデックスとは?IT用語としての意味やSEOでの使われ方を解説






インデックスとは、必要な情報を探しやすくするための「索引」のような仕組みを指す言葉です。
ITの分野では、データベース、検索エンジン、プログラミングなどで使われることがあり、文脈によって意味が少し変わります。SEOでは、Webページの情報が検索エンジンのデータベースに登録されることをインデックスと呼びます。
この記事では、IT用語としてのインデックスの意味を整理したうえで、SEOにおける仕組みや確認方法までわかりやすく解説します。
関連記事:インデックス確認とは ~SEO初心者がまずやるSEO対策その1~


インデックスとは
インデックスは英語のindexのことで、欲しい情報を探しやすくする仕組みのことです。ここではSEO的な意味のインデックスと、IT用語で使われるデータベースとしてのインデックスについて解説します。
データベースにおけるインデックスの意味
データベースにおけるインデックスの意味は、検索を効率化するための仕組みを指しています。
データベース内にある大量のデータを混沌とした状態で放置しておくと、検索した際に素早く結果を返すことができません。一方、情報をインデックスしておくとクエリを実行した際、その処理が高速化されます。つまり、データベースにおいてのインデックスの役割は、検索エンジンが高速で結果を表示するためのものです。
SEOにおけるインデックスの意味
インデックス登録とは検索エンジンがWEBページの情報を取得し、そのページの情報をデータベースに登録することです。インデックス登録が完了することで、WEBページの存在が検索エンジンに認識されます。
ユーザーの画面に検索結果としてWEBページを表示させるために、インデックスされることは必須事項です。インデックス登録されていないWEBページは検索エンジンに把握されていないため、SEOの評価を受けることもできません。
インデックス登録されることは、WEBサイトを運営するうえで重要な意味を持ちます。SEOの観点では、WEBページを作成したら可能な限り早くインデックス登録されることが大切です。
クローラーとインデックスの関係性
検索エンジンにとって、インデックスとクローラーはどちらも重要な要素です。そこでここでは、その関係性について解説します。
クローラーとは
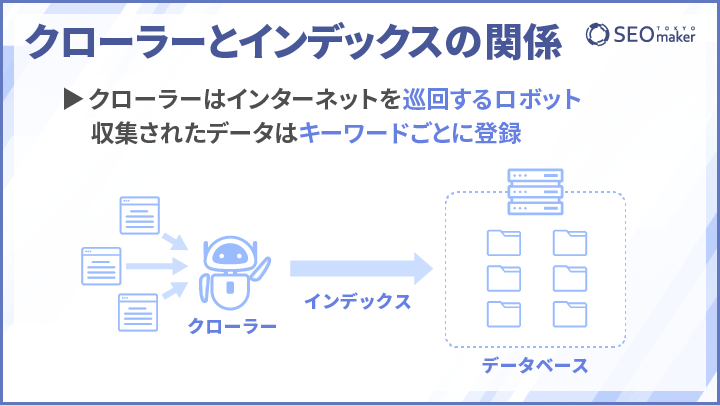
クローラーはインターネットをクロール(crawlつまり巡回)するロボットのことです。GoogleやBingといった検索エンジンは、独自に開発したロボット型検索エンジンにインターネットをクロールさせることで、WEBサイトの情報を収集しています。
検索エンジンのロボットであるクローラーは、インターネットを巡回しながらWEBページにアクセスし、情報を収集します。その後、クローラーによって収集されたWEBページのデータは、キーワードごとに検索エンジンのデータベースに登録されます。これがインデックス登録の主な仕組みです。
連携
クローラーとインデックスは連携して、最新のWEB情報を把握し、ユーザーに対して適切な検索結果を返しています。クローラーが定期的にWEBを巡回し、新しく追加されたページや更新情報を検出し、インデックス作業によってデータベースに格納されます。このような連携によって、検索エンジンは最新の情報を維持し、ユーザーの検索クエリに答えています。
コンテンツ品質とインデックスの関係性
コンテンツの品質とインデックスは、検索エンジンの最適化(SEO)において重要な関係性があります。そこでここでは、コンテンツ品質の観点からインデックスについて解説します。
コンテンツの品質評価
検索エンジンは、どんなWEBサイトでも等しく評価しているわけではありません。各WEBページごとに品質を評価し、その評価に基づいてインデックスの登録やランキングを決定します。コンテンツの品質の高いページは、ユーザーのニーズを満たしているため、検索結果でも上位に表示させます。
独自性の評価と重複の防止
コンテンツのオリジナリティもインデックスにおいて重要です。検索エンジンは重複したコンテンツを避け、独自性の高いページを評価します。インデックス作業では、重複コンテンツが検出されるとそれを排除し、独自性が高く信頼性が高いコンテンツはインデックス登録される可能性が高いです。
ユーザーエクスペリエンス
インデックスにおいては、ユーザーエクスペリエンスも考慮されます。検索エンジンは、ユーザーが使いやすい、見やすいWEBページを提供することを目指しているからです。インデックス作業では、レスポンシブデザイン、ページの読み込み速度などの要素を評価しています。
インデックスのメリット
インデックスはIT領域やWEBマーケティングにおいて重要な意味を持っています。なぜなら、インデックスされることで、検索エンジンからのアクセスが生じ、ユーザーが自社のことや商品・サービスについて認知してくれる可能性があるからです。
このようにインデックスされることによって、ターゲットにリーチできる機会が増え、将来的にコンバージョンやブランド認知向上につながります。そこで次に、インデックスされるための方法について解説します。
インデックスされるための方法
インターネットを巡回するクローラーは、WEBページのURLを利用してWEBコンテンツを検出して情報を収集します。クローラーにWEBページを検出させる方法はいくつかあり、積極的にクローラーにアクセスを促すことも可能です。
クローラーにWEBページを訪問させる方法には次のようなものがあります。
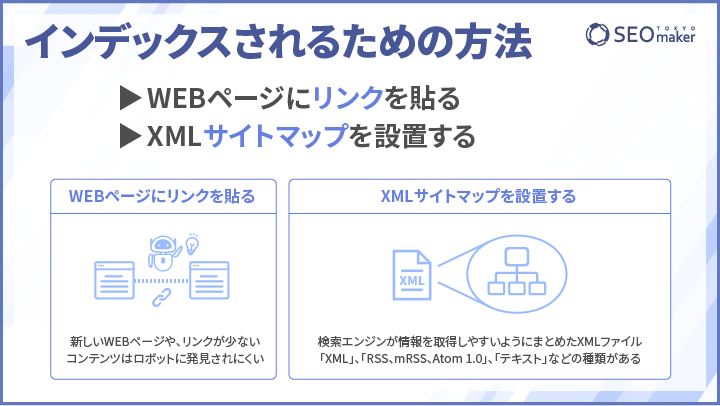
- WEBページにリンクを貼る
- XMLサイトマップを設置する
WEBページにリンクを貼る
早い段階でインデックス登録される必要がないWEBページであれば、クローラーが訪問するのを待つのも1つの方法です。
クローラーは、すでにデータベースに登録されているWEBページおよびそのページにリンクしているほかのWEBページをたどってインターネットを巡回しています。インデックス登録されるのを待つだけなので、特別な作業は不要です。
ただし、新しく作成されたWEBページやリンクが少ないコンテンツではロボットに発見されにくく、インデックス登録されるまでに時間がかかる可能性があります。
XMLサイトマップを設置する
XMLサイトマップとは、検索エンジンがWEBページの情報を取得しやすいようにまとめたファイルのことです。XML形式のファイルで作成されることからXMLサイトマップともよばれます。
新しく作成したWEBページやコンテンツ内容に変更があった場合にサイトマップによってURLを検索エンジンに通知することで、WEBサイトの存在や変更内容を速やかに検索エンジンに反映させる効果が期待できます。
Googleが対応するサイトマップには次のようなタイプがあります。
- XML
- RSS、mRSS、Atom 1.0
- テキスト
いずれかのタイプを選択して自動もしくは手動でサイトマップを作成したら、robots.txt ファイルに追加する、もしくはGoogleサーチコンソールに直接送信することでリクエストできます。
WordPressで作成しているWEBサイトであれば、プラグインでXMLサイトマップを作成することをご検討ください。プラグインを使用すれば容易にサイトマップを作成でき、更新作業をおこなった際も効率的な管理が可能です。プラグインにはXML SitemapsやAll In One SEO Packといったものがあります。
SEOの観点からみると、サイトマップは正確な内容で随時更新されることが重要です。手動で管理することで発生する人為的ミスや作業の手間を考慮するなら、サイトマップの更新は自動化してください。
HTMLサイトマップとは
WEBサイトに設置するサイトマップには、HTMLサイトマップとよばれるものもあります。HTMLサイトマップとはWEBサイト全体の構成を地図のように記載したものです。ユーザーが求める情報に辿り着く手助けをする役割も担います。
XMLサイトマップが検索エンジンのロボットにWEBサイトの情報を伝える役割を果たし、HTMLサイトマップはユーザビリティの向上に貢献します。いずれのサイトマップもSEOで評価されるWEBサイトに欠かせないものです。
インデックス登録させない設定
公開前のテストページや情報量が少ないページといったインデックスされたく無いページや検索エンジンの評価が不要なページの場合は、インデックスされることを拒否することもできます。
インデックス登録をブロックするためには、Googleが推奨するnoindexを使用してください。noindexを設定するためにはHTMLのhead要素内にmetaタグや、X-Robots-Tagレスポンスヘッダーを使用します。
なお、robots.txtファイルもインデックス登録をブロックしていると認識されます。しかし、ウェブページを検索結果に表示しないようにする目的でrobots.txtファイルを使用することは、Googleが推奨していません。
インデックスの状況を確認する方法
検索結果に自社WEBサイトを表示させるためには、インデックス登録されることが必須です。自社WEBサイトのページがインデックス登録されているか確認する方法は3つあります。
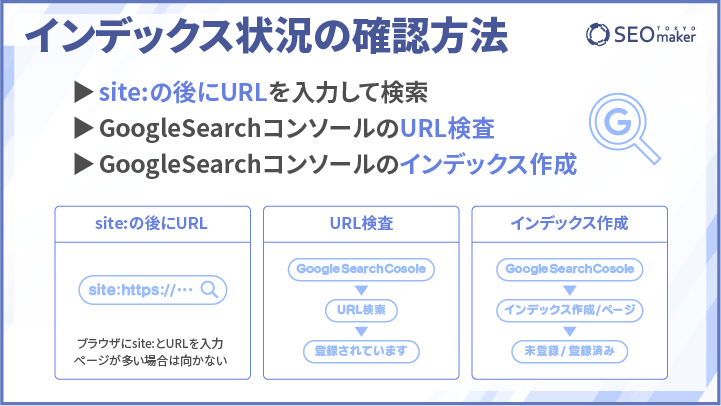
- site:のあとにURLを入力して検索
- GoogleSearchコンソールのURL検査
- GoogleSearchコンソールのインデックス作成
site:のあとにURLを入力して検索
WEBページがインデックスされているか調べるもっとも簡単な方法は、ブラウザにsite:と当該URLを入力して検索することです。インデックス登録されていれば、WEBページの説明が検索結果に表示されます。
ただ、この方法は調べたいWEBページが多い場合には適しません。その都度URLを入力しなければならないため手間がかかります。自社のWEBページのインデックス状況を調べるなら、Googleサーチコンソールを活用してください。
GoogleSearchコンソールのURL検査
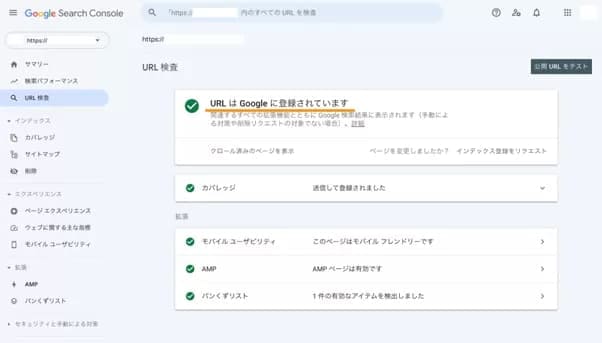
Googleサーチコンソールを利用すれば、インデックスされているか否かを容易に調べることが可能です。特定のWEBページのインデックス状況を確認する場合は、GoogleサーチコンソールのURL検査ツールを活用します。
GoogleサーチコンソールにログインしたらURL検索をクリックし、検査したいWEBページのURLを入力してください。
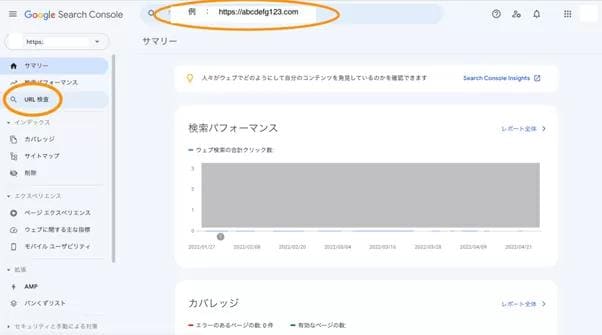
結果の画面に「URLはGoogleに登録されています」と表示されれば、インデックスされているため特別な対応は不要です。
GoogleSearchコンソールのページインデックス登録レポート
WEBサイト全体のインデックス状況をひと目で把握するなら、Googleサーチコンソールのページ インデックス登録レポートを活用してください。インデックス作成から「ページ」を参照すれば、インデックスの状況やWEBページで発生している問題を1つのページ内で確認することができます。
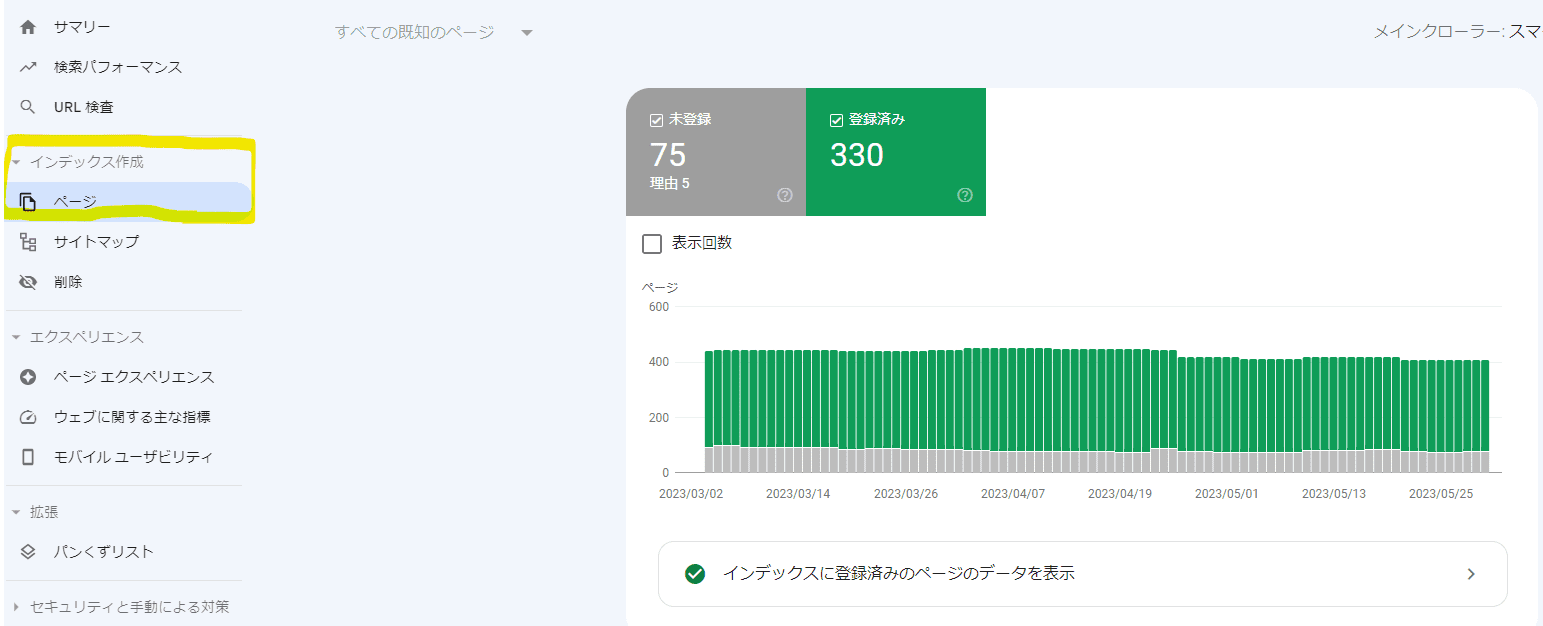
インデックス作成の「ページ」では、それぞれのWEBページを2つのステータスにわけて表示します。ステータスは次の4つです。
ページ インデックス登録レポートのステータス
| ステータス | 意味 |
| 未登録 | インデックスされていない |
| 登録済み | WEBページの登録が完了している |
参考ページ:GoogleSearchConsoleヘルプ
登録済みにはインデックスが完了しているWEBページの数が表示されています。
インデックスされていない場合の対処法
Googleは検索エンジンのロボットがWEBサイトに訪れるまでの期間は数日から数週間としています。WEBページを新しく作成もしくは変更したあと時間を置いてもインデックスされない場合は、検索エンジンにクロールをリクエストしてください。
クロールをリクエストする方法は2つあります。
- URL検査ツールからリクエスト
- XMLサイトマップを送信
クロールをリクエストするWEBページが少ない場合はURL検査ツールを、多い場合はサイトマップを使用すると効率よく作業できます。
URL検査ツールからリクエスト
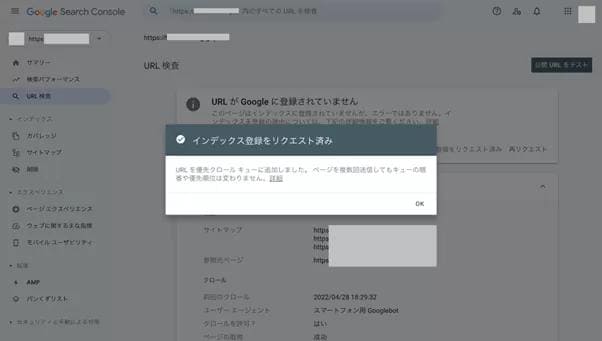
GoogleサーチコンソールのURL検査で当該WEBページのインデックス状況を調べます。結果画面に「URLがGoogleに登録されていません」と表示される場合は、インデックスされていません。
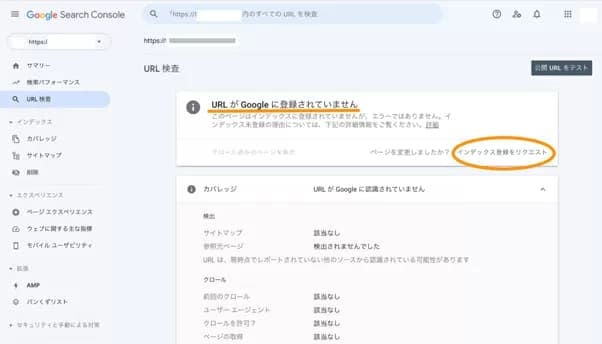
この場合は「インデックス登録をリクエスト」をクリックして、WEBサイトの情報をインデックスするようリクエストします。
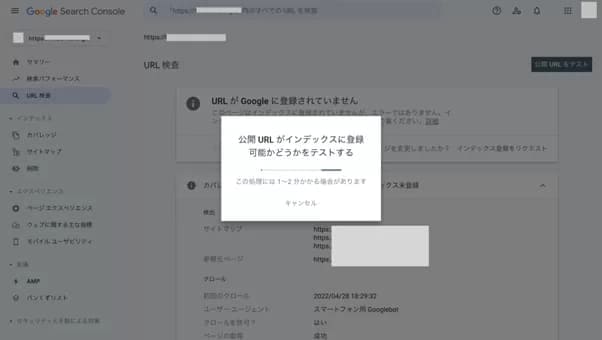
「インデックス登録をリクエスト済み」の画面が表示されれば、リクエストは完了です。
XMLサイトマップを送信
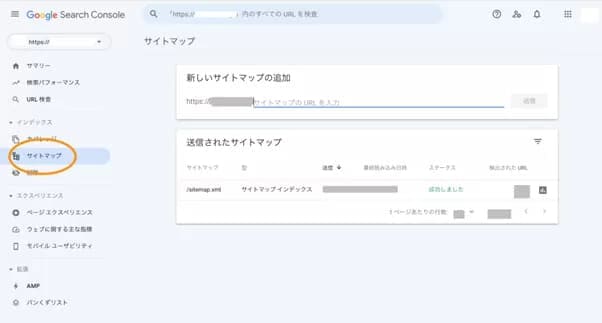
XMLサイトマップの情報はWEBサイトの更新や変更があるたびに更新される必要があります。
Googleサーチコンソールのサイトマップを開くと、登録済みのXMLサイトマップの更新状況を確認したり、新しいサイトマップを登録することができます。
インデックスされないときに見直すべきこと
検索エンジンがロボットは無数のサイトを巡回しています。WEBサイトの状況によってはロボットがWEBサイトを見落としたり、意図的にインデックスしないことも少なくありません。数日から数週間の期間待ってもインデックスされない場合は、WEBサイトに何らかの問題が発生している可能性を疑って確認してください。
インデックスされない理由となりえるため見直すべき要素には、次のようなものがあります。
- 重複コンテンツ
- ディレクトリ構造
- noindexやrobots.txt ファイル
- ペナルティ
重複コンテンツ
ほかのWEBページと重複している場合、重複コンテンツと判断されてインデックス登録されないことがあります。WEBページを作成する場合は必ずコピペチェックをおこなって、あらかじめ確認してください。
ディレクトリ構造
WEBサイトがわかりやすい構造であることは、ユーザビリティの観点のみならず検索エンジンのロボットがクロールしやすくする意味でも重要です。構造が複雑な場合、ロボットが隅々まで巡回できないことでインデックス登録されなくなる可能性もあります。
どのようにユーザーを誘導するか、全体構造を考えてシンプルなディレクトリ構造にするほか、パンくずリストも活用して誰もがわかりやすいWEBサイトを構築してください。なおパンくずリストの活用はGoogleが推奨しており、今や必須といえます。
noindexやrobots.txt ファイル
誤ってnoindexの設定をしている場合や、robots.txt ファイルで検索エンジンのロボットが巡回できないように設定している場合も、インデックス登録されません。
特にnoindexはWordPressの管理画面から容易に設定できるため、誤って意図しないページで設定している可能性も考えられるため注意してください。
インデックスのよくある質問と答え
ここでは、検索エンジンのインデックスについてよくある質問と答えをお伝えします。
Q:インデックスの更新頻度はどれくらい?
Answer)更新頻度は検索エンジンや各WEBページの更新頻度などによって異なります。一般的にはよく更新されるWEBページは、短期間でクローラーが巡回します。このように必要性の高いWEBページを集中的に巡回することで、クローラーのリソースを節約しています。
Q:インデックスされるためには何に注意すれば良い?
Answer)コンテンツの品質向上やユーザーのニーズに応えることが重要です。具体的には、キーワードの適切な使用や分かりやすい文章構成、適切なメタデータの設定などが挙げられます。その他、クローラビリティを確保するために正しいHTML構造などにも配慮してください。
Q:ページが除外されることはある?
Answer)はい、検索エンジンのインデックスから除外されることはあります。理由としては、WEBページが検索エンジンのガイドラインに違反している場合やコンテンツが重複しているなどのことが考えられます。
Q:削除されたページは再びインデックスされる?
Answer)何かの理由によってインデックスから削除された場合、WEBページを更新して再度、クローラビリティを確保してください。WEBページのコンテンツやメタデータ、noindex指定の解除などを試みることによって、再度インデックスされる可能性があります。
まとめ
検索エンジンのロボットにクロールされ、さらにインデックス登録されることは、WEBサイトを運営するうえでの大前提です。インデックス登録されなければユーザーの目に触れることもなく、当然検索エンジンの評価を受けることもできません。WEBサイトを作成するために費やした時間や労力、費用は無駄になります。何らかの問題によってインデックスされないといった事態を回避するために、Googleサーチコンソールをチェックすることを習慣にしてください。Googleサーチコンソールを活用してWEBサイトが健全に機能していることを常に把握しながら、問題が起きた場合は一刻も早く対処できる体制を整えることが大切です。適切にWEBサイトを作成していれば検索エンジンのロボットに巡回され、インデックス登録されます。それに加えて積極的に検索エンジンにWEBサイトの存在をアピールすれば、インデックス登録されるまでの時間を短縮することも可能です。攻めの姿勢で少しでも早くWEBサイトがインデックスされるような対策をとってください。

この記事の監修者

日本大学法学部卒業、広告代理店で12年間働いている間、SEOと出会い、SEO草創期からSEO研究を始める。SEOを独学で研究し100以上のサイトで実験と検証を繰り返しました。そのノウハウを元に起業し現在、11期目。営業、SEOコンサル、WEB解析(Googleアナリティクス個人認定資格GAIQ保持)コーディング、サイト制作となんでもこなす。会社としては今まで2000以上のサイトのSEO対策を手掛けてきました。




















