
LLMOとは?AI最適化の考え方と実践手順を解説
 近年、ChatGPTやGoogle AI Overviews、Perplexityなどの生成AIを使って情報収集を行うユーザーが急速に増えています。これまでのWeb集客は、Google検索で上位表示され、ユーザーにクリックしてもらうことが中心でした。
近年、ChatGPTやGoogle AI Overviews、Perplexityなどの生成AIを使って情報収集を行うユーザーが急速に増えています。これまでのWeb集客は、Google検索で上位表示され、ユーザーにクリックしてもらうことが中心でした。
しかし今は、検索結果を読む前に、AIの回答そのものを参考にして比較・検討・意思決定する場面が増えています。こうした変化のなかで注目されているのが、LLMO(Large Language Model Optimization)です。
LLMOとは、生成AIに自社の情報を正しく理解・参照・言及されやすくするための最適化を指します。
こちらの動画でもLLMOについて詳しく解説していますので、ご視聴ください。
本記事では、LLMOの意味やSEOとの違い、注目される背景、2026年に押さえるべき具体的な対策までを、一次情報を交えながらわかりやすく解説します。


LLMOとは
LLMOとは、Large Language Model Optimization の略で、日本語では「大規模言語モデル最適化」と訳されます。
簡単にいうと、ChatGPT、Google AI Overviews、Perplexity、Copilot などの生成AIが回答を作る際に、自社のコンテンツやブランドが理解・参照・言及されやすい状態をつくるための最適化です。
従来のSEOが「検索結果で上位表示され、クリックを獲得すること」を中心に考えてきたのに対し、LLMOは「AIの回答の中で自社情報が取り上げられること」を重視します。
ただし、LLMOはSEOと対立する概念ではありません。Googleは、AI Overviews や AI Mode に表示されるための特別な追加要件はなく、まずは通常のSEOベストプラクティスが有効だと案内しています。つまり、SEOを土台にしつつ、AI時代に合わせて情報設計を最適化する考え方がLLMOです。
一言でいえば、SEOが「検索エンジンに選ばれる最適化」なら、LLMOは「AIに選ばれる最適化」です。
なぜ今LLMOが注目されているのか
LLMOが注目されている最大の理由は、ユーザーの情報収集行動が変わってきたことです。
これまでの検索行動は、
検索 → 検索結果をクリック → サイト訪問 → 比較・検討 → CV
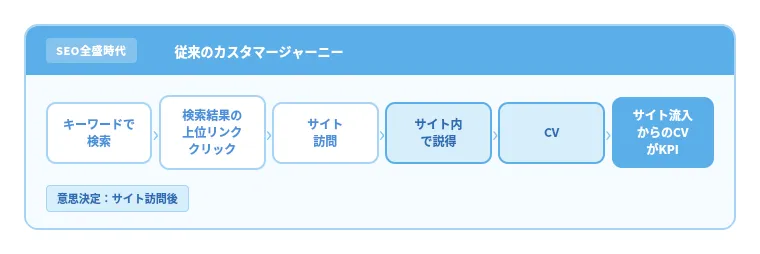
という流れが中心でした。
しかし現在は、
AIに相談 → AI回答・推薦を確認 → 必要に応じてサイト訪問 → CV
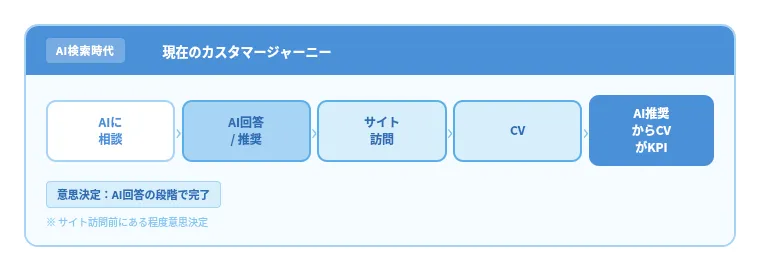
という流れが増えています。意思決定のタイミングが「サイト訪問後」から「AI回答確認時」へ前倒しになっています。Googleも2025年3月に、AI Overviews の拡大と AI Mode の導入を案内しており、より複雑な質問や比較をAIで支援する方向を明確にしています。
つまり、これからのSEO担当者は「クリックされる前に、AIの回答で候補に入っているか」を意識しなければなりません。この変化に対応する考え方として、LLMOの重要性が高まっています。
一次データで見るLLMOの現在地
LLMOは話題先行に見えるかもしれませんが、実際に、生成AI経由の流入とCVが増加傾向にあるという1次情報が多数あります。
生成AI流入・CVの主要データ
- AI流入セッション増加率:+527% (引用元:Previsible社の調査/Search Engine Landの記事)
- 生成AIトラフィック増加:+796%(引用元:WebFX社/Inside AI Traffic’s 796% Growthの記事)
- 生成AIコンバージョン増加:+6,432%(引用元:WebFX社/Inside AI Traffic’s 796% Growthの記事
- ChatGPT経由CVR:15.9%(引用元:Seer Interactive社/POSITION DIGITALの記事)
- Googleオーガニック経由CVR:1.76%(引用元:Seer Interactive社/POSITION DIGITALの記事)
- LLM訪問者のCVR優位性:4.4倍(引用元:Semrush【米国】の調査記事)
2025年7月のAhrefsの調査では、ChatGPT経由の流入は検索全体に比べるとまだ小さく、総リファラルの約0.19%規模とされていました。一方で、Search Engine Land が紹介した Previsible の 2025 AI Traffic Report では、AIトラフィックが前年同期比 527% 増と報じられています。さらに、Adobe Analyticss社の調査データでは、生成AI経由流入が2024年7月〜2025年2月で10倍超へ増加(小売+1,200%、旅行+1,700%)との報告もあります。
これらのデータから見ると規模はまだ小さくても、伸び率と質の高い流入という点で無視できないチャネルになってきています。
Googleの考えと弊社の考え
Google Search Centralの「AI 機能とウェブサイト」でも、AI OverviewsやAI Modeで表示されるための追加要件はないと公表しています。
SEO のベスト プラクティスは、引き続き Google 検索の AI 機能(AI による概要や AI モードなど)でも有効です。AI による概要や AI モードにコンテンツが表示されるための追加の要件はなく、別途特別な最適化を行う必要もありません。ただし、SEO の基本のベスト プラクティスを再度確認することは常に効果的な方法です。
Googleは、従来のSEOベストプラクティスを継続することが有効であるという立場です。SEOが「検索エンジンに理解されるための最適化」であるのに対して、LLMOは「AIに理解され、選ばれ、引用されるための最適化」と位置づけられます。LLMOはSEOとは切り離された概念ではなく、SEOを土台として成立する最適化の一種です。
これはあくまで弊社の見解ですが、SEOとLLMOの関係は、「親子」にたとえられると思います。 SEOが母親だとすれば、LLMOはその子どもにあたります。 SEOが子供のLLMOを育て、見守り成長を促している存在。ですので、SEOとLLMOを比較や切り離しをするのではなくてSEOの母体ですくすくと育って産み落とされた赤ちゃんがLLMOです。これからもSEO(母)の愛情がたくさん必要です。
よって、このLLMOを育ているには、SEO全体の施策の中で、とくにLLMOに寄与する領域へ重点的に取り組む姿勢が求められます。LLMOはSEOの基盤のうえに成り立つ最適化である点を押さえておくとよいでしょう。
LLMOとSEOの違い
LLMOとSEOの大きな違いとして、KPIの違いが挙げられます。SEOでは検索順位やCTR、オーガニック流入、CV率といったクリックを起点とする指標が中心でした。しかしLLMOでは、AI Overviewsに引用されているか、ChatGPTやClaudeの回答内でブランド名が言及されているか、推奨候補として提示されているか、引用元リンクが表示されているか、さらにはAI経由の流入(LLM referral)がどの程度発生しているかといった点が評価軸になります。クリックの有無よりも、「AIが自社を情報源として選んだかどうか」が成果の基準になる点が特徴です。
競争の構造も両者では大きく異なります。SEOが検索結果ページ上の10枠前後をめぐる競争であるのに対し、LLMOではAIが提示する回答内のごく限られた情報源、多くても1〜5枠程度を争う構造になります。表示される枠が極端に少ない分、選ばれる難易度は高くなりますが、その分、引用された際の影響力や信頼性の重みは相対的に大きくなります。
もっとも、SEOとLLMOの間には変わらない本質も存在します。表示形式や評価指標は異なっても、どちらも最終的にはユーザーの意思決定を助けるために、正確で価値のある情報を提供することを目的としています。高品質な一次情報や、裏付けのあるデータ、透明性の高い説明が重視される点は共通しており、検索エンジンも生成AIも、不正確な情報や信頼性の低い情報を優先しないという基本思想に基づいています。
| 比較項目 | SEO | LLMO |
| 最適化の対象 | 検索エンジン(Google,Bingなど) | 生成AI(ChatGPT/Claude/AI/Overviewsなど) |
| 目的 | 上位表示による流入増・CV獲得 | AI回答での引用・推薦によるブランド想起・指名・AI経由流入 |
| 競争枠 | 検索結果10枠 | AI回答内の1~5枠(より狭い) |
| ユーザー行動 | 検索→クリック→訪問 | 質問→AI回答→意思決定 |
| 主要KPI | 検索順位/CTR/オーガニック流入/CV率 | 引用有無/回答内登場率/推奨扱い/LLMreferral/ブランド共起 |
| 注力施策 | 内部SEO,コンテンツSEO,外部リンク、EEAT,CoreWebVital | エンティティ強化、AIに引用されやすい構造、構造化データ、llms.txt、EEAT、サイテーション |
| 共通の本質 | EEAT(経験・専門性・権威性・信頼性) | EEAT(経験・専門性・権威性・信頼性)、実在性の担保 |
| 共通の評価軸 | 高品質な一次情報・透明性が評価される | 高品質な一次情報・透明性が評価される |
| 現在の流入比率 | 55億回/日 1兆8600億回/年(前年比0.51%減少)AI関連の34倍 | 2億3310万回/日 552億回/年(前年比80.92%増加)SEOの34分の1 |
LLMOを導入すべき理由とメリット
LLMOの最大のメリットは、生成AIの新しい検索環境において自社や商品の存在感を高められる点にあります。AIは、従来の検索エンジンのようにリンク一覧を提示するのではなく、コンテンツを要約して直接的な回答を生成するため、そこで自社が言及されればブランド構築やトラフィックの増加に役立ちます。
今後、AI検索の利用は着実に増加していくことが予想されるため、早期にLLMOを導入することは、自社の集客とブランド構築にとって重要な戦略となるはずです。また、AI検索経由の訪問者は、従来のオーガニック検索経由の訪問者よりも、コンバージョン率が高い傾向にあるのもメリットの1つです。
LLMOのメリットを一言で表すと、自社サイトに対するアクセス流入を確保できるということです。このメリットを大きく分けると、次のように分類できます。
- 現状のLLM利用者にリーチできる
- 将来的なトラフィックの確保につながる
このほか、検索結果で上位表示すると、生成AIに自社サイトが引用される機会が増えることから、次のような利点もあります。
- SEO対策と相性がよい
現状のLLM利用者にリーチできる
LLMOを導入することで、LLM(大規模言語モデル)が組み込まれている生成AIの利用者にリーチできます。
2022年に生成AIのChatGPTが公開され、その5日後には100万人の登録を集めるなど、世界中で大きな反響を呼びました。国内においても、2024年に携帯電話キャリアのソフトバンクがPerplexity Proのお試しキャンペーンを展開して話題となりました。このように、生成AIが注目を浴び続け、利用者が増加しています。
将来的なトラフィックの確保につながる
LLMOを導入すると、将来的なトラフィック確保の施策になります。国内で生成AIを「積極的に利用する方針」の人の割合は、2024年時点で個人=9.1%、企業=18.6%となっていることが総務省の調べで明らかになっています。さらに、企業においては、「限定的に利用する方針」と回答した人を含めると、全体の40%以上の法人が生成AIに興味を持っていることがわかっています。そのため、とくにBtoBビジネスのWEB集客において、今後さらにLLMOの重要性が高まる可能性を秘めています。
SEO対策と相性がよい
LLMOの導入の利点には、SEO対策と親和性が高い点が挙げられます。そもそもLLMを代表するChatGPTなどの回答文は、インターネット上の情報をもとに構成されます。とくに、Google検索エンジンの検索結果の上位ページがソースになりやすい傾向がみられます。そのため、LLMOの施策を進めるうえでは、SEO対策が必須となります。逆にいうと、SEO対策と同時並行してLLMOに取り組むことが可能です。
LLMO対策の核となる考え方
企業がLLMOに取り組む際の土台となる考え方を解説します。ここで扱う内容はテクニックではなく、LLMOの根幹に位置づけられるものです。いずれか一つでも欠けてしまうと、AIが企業を正しく理解できず、引用・推薦の対象から外れるリスクが生じます。
LLMOはSEOを土台としつつも、単なるSEOの延長にとどまりません。検索・AI・ブランド構築が統合された新しい「企業認知戦略」と捉えることができます。ここからは、その中心となるテーマとして「AIに理解される企業はどのような姿か」を深く掘り下げていきます。
クエリ ファンアウトを理解する
LLMOを理解するうえで最も重要な概念が、クエリ ファンアウト(Query Fan-out)です。
クエリ ファンアウト(Query Fan-out)は、ユーザーが入力した一つの質問(クエリ)を、AIが複数のサブクエリに分解し、同時並行で検索・取得する仕組みです。GoogleもAI モードの内部にこの手法を採用しており、質問をサブトピックへ分割して複数の検索を走らせ、得られた情報を統合し回答を生成するプロセスを明らかにしています。
従来のSEO検索は基本的に「1クエリ=1検索」であり、ユーザーは必要に応じて追加検索を重ねて情報を集めていました。しかしAI検索では、質問が複雑になるほどAIがユーザーの代わりに複数回の検索を実行し、情報を収集して統合する構造に変わっています。これがクエリ ファンアウトです。
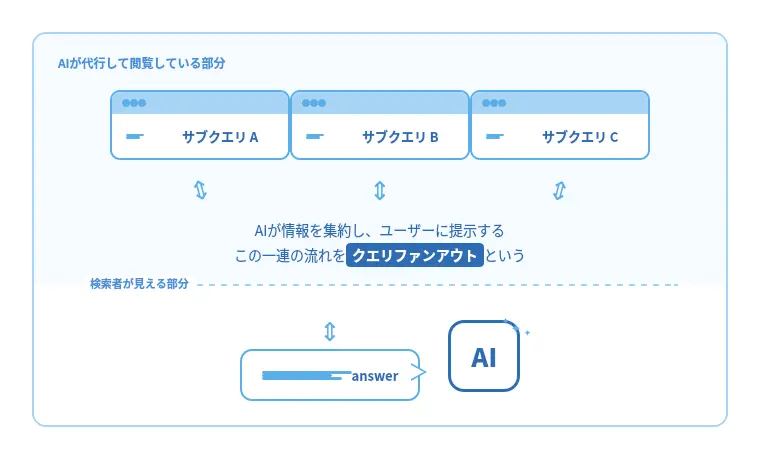
たとえばユーザーが「オーストラリアでSEOを成功させるには、どの州を優先し、どのようなコンテンツ戦略を取るべきか」と質問した場合、従来検索ではユーザー自身が「オーストラリア SEO 市場」「ニューサウスウェールズ州 産業 検索需要」「ビクトリア州 B2B SEO」など、検索を繰り返す必要がありました。
一方、AI検索(クエリ ファンアウト)では、ユーザーは最初の一回だけ質問し、AIが裏側で、市場全体の整理、州別の産業構造と検索意図、成功事例、業界別の施策、失敗パターンなどに分割したサブクエリを同時に実行し、まとめた上で最終回答を出してきます。
従来はユーザーが検索を重ねて情報を集めていたところを、生成AIが一度の質問で代替し、多面的な探索を完了させるようになったわけです。
このプロセスを視覚的に理解したい場合には、クエリ ファンアウトの動きを短時間で把握できる動画が参考になります。次の動画では、AIがどのようにサブクエリを展開し、情報を統合して回答を導き出すのかを簡潔に示しています。
・AI Mode Query Fan-Out(33秒)
では、なぜクエリ ファンアウトが生まれたのでしょうか。背景には、AI検索が「検索行為そのものの短縮」を目指しているという目的があります。現実のユーザー行動はすでに「一度で答えを得たい」「追加検索は手間」「情報収集より結論がほしい」という方向へ強く傾いています。GoogleがAI Modeを「より深くウェブを掘り、適切な情報をまとめる体験」として位置づけるのも、このニーズに応える意図です。
その結果、クエリ ファンアウトは「ユーザーの検索労働をAI側が吸収する」技術として設計されたと考えられます。つまり、一回の質問で多段階の検索(multi-step search)を完結させる技術として設計されたといえます。
厳密な内部構造は非公開ですが、公式情報やAI検索の技術構造から推測すると、少なくとも次のような流れで動いていると考えます。

クエリ ファンアウトの構造を理解すると、LLMO対策の方向性も明確になります。このように適したコンテンツやサイト設計を進めることで、AIによる引用や推薦の頻度を大きく高めることが可能です。
LLMO対策
LLMO対策は、4つの柱で考えます。LLMO戦略策定、LLMO内部対策、LLMO外部対策、LLMO効果測定です。まず、一番初めに行うLLMO戦略策定では、AIに選ばれる戦略を5つのマップに分けて体系化します。どういったプロンプトで選ばれたいのか、そしてどういったプロンプトがCVまでつながるのか戦略を策定します。次に戦略に合わせて、サイトを最適化するLLMO内部対策を行います。LLMO内部対策は主に、サイトに施す施策です。コンテンツ部分(コンテンツLLMO)とテクニカル部分(テクニカルLLMO)に分かれます。

LLMO戦略策定
まず、一番初めに行うのは「LLMO戦略策定」です。最初に取り組むのがプロンプトマップです。AIにどんな問いで登場したいかをペルソナ別・AIチャネル別に定義し、商談性・AI適性・差別化余地のスコアで優先順位を明確にします。次にAI選定軸マップでは、AIが企業を選ぶ際に使う評価軸を特定し、自社の現状達成度との乖離を数値化することで、強化すべきポイントを具体的なアクションとして整理します。
RAG接点設計マップは、AIがRAG(検索拡張生成)で情報を参照する媒体・クエリ・チャンネルをクエリ系・媒体系に分けて網羅し、自社がどこに露出すべきかを設計します。証拠設計マップでは「なぜこの会社か」をAIが引用できる形の根拠ステートメントとして設計・配置し、信頼性の裏づけを整備します。そして最後のクエリファンアウト型トピッククラスターでは、AIが質問をサブクエリに展開する経路に合わせて、Hub・Spoke・Supportingの3層構造でコンテンツを設計し、AIの情報収集ルートを面として押さえます。
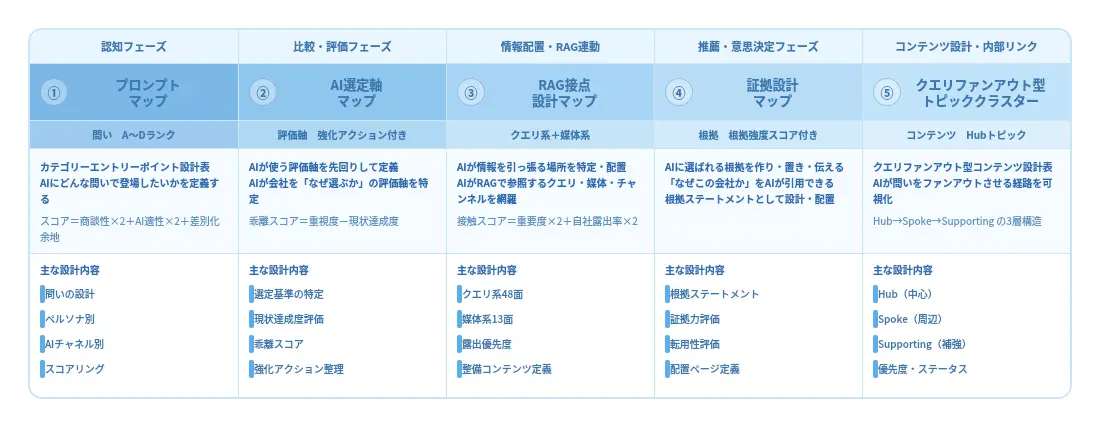
この5つのマップによる戦略策定が、続く内部対策・外部対策・効果測定の土台となります。場当たり的な施策ではなく、AIの思考プロセスに沿った構造的な設計を最初に行うことが、LLMOにおいては最も重要なステップといえます。
LLMO内部対策
LLMO内部対策とは、自社サイトをChatGPTやGeminiなどの生成AIに引用・推奨されやすい状態に整えるための施策群です。コンテンツ対策・技術対策・サイト構造対策・信頼性対策・運用体制対策の5カテゴリで構成されており、戦略策定で描いた設計図を実際のサイトに落とし込む段階に当たります。

コンテンツLLMO対策では、生成AIが展開するサブクエリを分析し、AIが理解・統合しやすいトピッククラスター構造を設計するところから始まります。また、結論先出しやQ&A形式・比較・手順といった文章構造を採用することで、AIが回答に使いやすいコンテンツへと整えます。既存のサービスページや記事も同様の観点でリライトし、一次情報・実績・事例といったエビデンスを加えることで専門性と信頼性を底上げします。
技術部分のテクニカルLLMO対策では、FAQや組織情報などを構造化データとして実装し、AIがサイトの情報を機械的に正しく読み取れる環境を整えます。見出し階層の最適化やllms.txtの設置によってAIクローラーへの対応も行い、クロールしやすさや表示速度・UXの改善を通じてAI評価の土台を固めます。
サイト構造対策では、内部リンクを論理的に設計することでAIが情報の関係性を追いやすくし、ディレクトリ構造やURL階層を整理することでサイト全体が「何の専門サイトか」を明確に伝えられる知識ネットワークとして機能させます。
信頼性対策では、企業名・サービス名・専門領域・実績といったエンティティ情報をサイト全体で一貫性ある形に整理し、AIが「実在する信頼できる企業」として認識できる状態を作ります。E-E-A-T(経験・専門性・権威性・信頼性)を明文化した運営者情報の整備もこの段階で行います。
運用体制対策では、ChatGPTなどでの自社・競合の扱われ方を定期的に確認しながら改善課題を可視化し、優先順位をつけて施策を継続できる社内体制を構築します。外部に頼り切らず内製化できる運用設計を目指すことが、LLMOを長期的に機能させるうえで重要なポイントです。弊社では、LLMO対策を内製化できるサービスもありますのでご相談ください。
LLMO外部対策
LLMO外部対策とは、外部からの言及・実績・評価を通じて、生成AIに「信頼できる企業」「語るべきブランド」として認識させる施策です。内部対策がサイト内の構造やコンテンツを整えてAIに「理解してもらう」ことを目的とするのに対し、外部対策は第三者の文脈・言及・評価を積み重ねることでAIに「信頼してもらい、語ってもらう」状態を作ることを目的とします。

ブランディング施策(権威性の構築)では、業界メディアや専門サイトへの掲載、プレスリリースの配信・引用促進、専門誌への寄稿記事設計、書籍・ホワイトペーパーなどの知的資産活用を通じて、AIが参照する第三者の文脈でブランドの権威性を確立します。生成AIは信頼性の高い外部情報源を根拠に回答を生成するため、そうした媒体に自社情報が掲載されていることが重要な評価シグナルとなります。
サイテーション・外部リンクの獲得では、高品質な外部リンクの戦略的な獲得に加え、リンクの有無を問わない第三者言及(サイテーション)を増やす施策を行います。外部メディア・Q&Aサイト・比較サイトなどで語られる自社に関する情報を一貫させることで、AIへの信頼シグナルを強化します。
SNS・動画による専門性の可視化では、X・Instagram・YouTube等の各プラットフォームで専門情報を継続的に発信し、AIが参照できる外部情報源を増やします。発信テーマと表現を統一することで、「この分野の専門企業」としてAIに定着させるエンティティ強化にもつながります。
実績・事例を軸にした第一想起の形成では、顧客事例や導入実績を外部メディア・比較サイトに公開し、具体的な数値や成果データをAIが引用しやすい形で整備します。「○○といえば△△」という文脈を外部で統一することで、AI内でのブランドの第一想起を形成することが最終的なゴールです。
内部対策・外部対策・コンテンツLLMOの3つを組み合わせることで、AIに継続的に推薦される状態を最大化できます。
LLMOのKPI設定と効果測定
LLMOにおけるKPI設計は、クリックや流入を中心とした従来のSEO指標だけでは不十分です。生成AIの回答では、クリックされないまま認知や理解、意思決定が完結するケースが増えており、成果の捉え方そのものを見直す必要があります。こちらの動画で詳しく説明していますのでご覧ください。
LLMOの効果測定の指標は、、AI SOV、AIリファラル、ゼロクリックの3つです。AI SOVは、特定テーマにおいて生成AIの回答内で自社やサービスがどれだけ言及・引用されているかを測る指標で、AIの中での認知と評価の広がりを示します。AI時代における「検索結果シェア」は、「回答内シェア」へと置き換わりつつあります。
AIリファラルは、生成AIを起点として実際に発生した行動を測る指標です。AI経由のユーザーは事前理解が進んでいるため、流入数は少なくてもCV率や商談化率が高くなりやすく、ビジネス成果への直結度を示す重要なKPIとなります。
ゼロクリック指標は、サイト訪問が発生しなくても、AI回答内でどれだけ認知・理解・信頼が形成されたかを測るための指標です。ブランド言及や評価文脈、指名行動の変化などを通じて、クリックに現れない影響を可視化します。
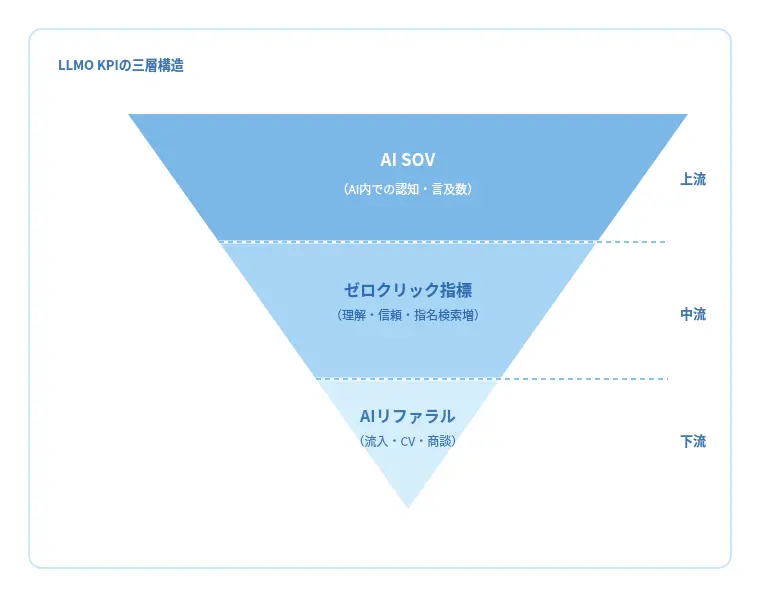
重要なのは、これらを個別に追うのではなく、AI SOV(認知)→ゼロクリック指標(理解・信頼)→AIリファラル(行動・成果)という流れで段階的につなげて設計することです。LLMOのKPIとは、アクセス数ではなく、AIの思考プロセスの中にどれだけ深く入り込めているかを測るための指標設計だと言えます。
最適化の具体的ステップ(PDCAの回し方)
ゼロクリックKPIを設定するだけでは、LLMOの成果は生まれません。重要なのは、その指標を基準に「AIの中で自社がどのように認識されているか」を継続的に改善していく運用です。LLMOのPDCAは、AIの認識を起点に回すシンプルな型にすることで、再現性が高まります。
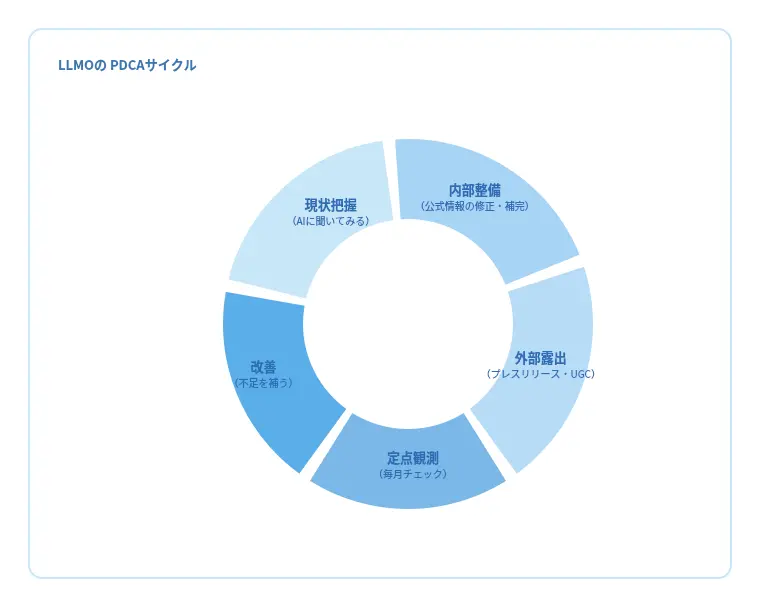
まずは現状把握として、自社名や重要テーマを生成AIに質問し、どのような文脈で言及されているか、誤認や不足がないかを確認します。次に、その結果をもとに公式情報を整備し、一次情報の補強、FAQや専門ページの拡充、構造化データや著者情報の明確化によって、AIが安心して引用できる公式リファレンスを構築します。
並行して、プレスリリースや事例公開など外部露出を強化し、第三者評価という信頼シグナルを積み上げます。その後、同一プロンプトによる定点観測を継続し、AIの回答がどのように変化したかを測定します。誤りやズレが見つかれば公式情報を修正し、露出しにくいテーマは成果導線を見直します。
この「認識の確認、情報整備、外部証拠の強化、定点観測と改善」のサイクルを回し続けることで、AI時代においても可視性と成果を着実に高めていくことが可能になります。
| 最適化の具体的なステップ | |
| 現状診断 | 自社名、製品名、検索クエリでAI回答をチェックし、掲載の有無と正確性を記録。 |
| 情報整備 | 一次情報の追補、FAQの拡充、構造化データの追加、著者・監修表記などLLMO対策を行う。 |
| 露出の仕掛け | プレス・業界団体・顧客事例の公開(引用されやすい形式で実装する)。特にサービスページと実績・導入事例ページの作成。 |
| 定点観測 | 毎月同一プロンプトで回答ログを保存(ツール運用可)。 |
| 改善 | 誤りは訂正根拠を添えて更新。AI体験での露出が難しいテーマは資料請求、相談CTAへ導線強化。 |
LLMO計測ツール
AI時代の効果測定はまだ発展途上ですが、すでに実務で活用できるツールが登場し始めています。代表例が、Ahrefsの「Brand Radar」とSemrushの「AI Visibility Toolkit」です。これらはChatGPTやGemini、AI Overviews、Perplexityなど複数のAIプラットフォームを横断し、回答内でのブランド言及数や引用状況、競合との比較を可視化できます。
特に、ゼロクリックKPIの中心となる「回答占有率」や「ブランド言及数」を直接計測できる点が特徴で、AI上での存在感を定点観測する基盤として有効です。どの質問で、どのAIが、自社や競合をどう扱っているかを把握することで、LLMO施策の影響を具体的に検証できます。
もっとも、この分野はまだ黎明期であり、ツールだけに依存するのは現実的ではありません。AIの回答内容を自ら確認する手動チェックと組み合わせ、変化を継続的に記録・改善に活かす姿勢が重要です。AI内で「どれだけ語られているか」を可視化することが、LLMO改善の第一歩になります。
| ツール名 | 提供会社 | 特徴 | 対応AI/領域 | 公式URL |
|---|---|---|---|---|
| Brand Radar | Ahrefs | 生成AI回答内でのブランド言及/可視性を測定・比較。AI回答のシェア・オブ・ボイス等の指標が確認できる AI可視性ツール。 | ChatGPT / Gemini / AI Overviews / Perplexity / Copilot など | https://ahrefs.com/brand-radar |
| AI Visibility Toolkit | Semrush | AI回答内でのブランド露出、引用状況、競合比較などを可視化するツール。AI検索可視性スコアなどの指標が確認可能。 | AI Overviews / ChatGPT系 / 複数AI検索 | https://www.semrush.com/ai-seo/overview/ |
| Profound AI | Profound | 生成AI検索/回答内でのブランド可視性を追跡・分析・最適化するプラットフォーム。ブランド言及状況や競合比較インサイトの提供。 | ChatGPT / Google AI Mode / 複数LLM | https://www.tryprofound.com/ |
| Peec AI | Peec AI | 複数AI検索/回答でのブランド露出の追跡、可視性スコアや競合比較を提供するブランド分析ツール。 | ChatGPT / Gemini / Perplexity など | https://www.peec.ai/ |
| Rankscale AI | Rankscale | AI検索/回答内のブランド登場状況や回答内位置を分析する可視性ツール。 | ChatGPT / AI検索系 | https://www.rankscale.ai/ |
LLMO対策のコツ
自社サイトのコンテンツが生成AIに引用されるためには、一定の条件がありますが、まず基本的なSEO対策ができていないサイトは、まずはSEO対策から始めることをお勧めします。
| 生成AIに引用される条件 | 主な対策 |
|---|---|
| AIモデルにサイト情報を提供する | 構造化データ |
| 信頼性が高い情報を発信する | エンティティ強化/E-E-A-T / コンテンツSEO |
| 検索結果で上位表示する | SEO対策 |
たとえば、ChatGPTは、インターネット上のデータを参考にして回答テキストを生成する仕組みを採用しています。生成AIの回答文に自社サイトが引用されるためには、「検索結果で上位表示する」ことも有益に働きます。このように、LLMO対策につながる具体的な施策としては、次のようなものが挙げられます。
- エンティティ強化
- 構造化データを設置する
- E-E-A-Tの評価を高める
- コンテンツSEOで独自性が高い情報を発信する
- SEO対策で検索順位を上げる
エンティティを強化する
エンティティとは、検索エンジンが「固有の意味を持つもの」として認識する対象のことです。例えば、apple(リンゴ・企業名)。Googleはキーワード一致ではなく、「そのキーワードが指す実体(エンティティ)」を理解して検索結果を表示しています。Googleに「誰について語っているか」「何について書かれているか」を明確に伝えることが大切です。EEATにもつながります。
構造化データを設置する
構造化データとは、検索エンジンにWEBサイトやページの情報を提供するためのデータのことです。とくにFAQ(よくある質問)を構造化データ化すると、生成AIにピックアップされやすく、LLMOの施策に影響します。
関連記事:構造化データとは
E-E-A-Tの評価を高める
E-E-A-Tとは、Google検索エンジンがWEBサイトの品質を評価する指標のことです。つまり、WEBサイトのE-E-A-Tが高いと、情報の信頼性が高いと評価づけられるということです。そして、生成AIが回答文を生成する際には、信頼性が高い情報を組み合わせることが重要となります。そのため、E-E-A-Tの評価が高いWEBサイトのページは、生成AIに引用されやすくなります。
関連記事:E-E-A-Tとは
AIが好む情報設計でコンテンツSEO対策を行う
コンテンツSEOとは、WEBサイトのコンテンツ品質を高める施策のことです。具体的には、サイト構成からページ内のテキスト作成まで幅広い手法が存在します。コンテンツSEOは、LLMOの改善に大きな影響を与える施策です。
なかでも、一次情報に代表されるオリジナルコンテンツの作成がLLMOと親和性が高い施策となっています。オリジナルコンテンツを作るということは、該当する情報に対する競合ページが存在しないことを意味します。たとえば、「AはBである」ことを伝える独自情報を自社ページで掲載している場合、生成AIが「AはBである」ことを載せる際の情報源として、ほぼ確実に自社ページがピックアップされることになります。
関連記事:コンテンツSEOとは
SEO対策で検索順位を上げる
そもそも、SEO対策とは、主にGoogle検索エンジンの検索結果に自社サイトのページを掲載する施策のことです。一般的には、検索順位を高めて1位を獲得する、ないしは1ページ目にランクインすることを目指していきます。高順位のWEBページは、生成AIに引用される傾向がみられます。そのため、LLMO対策を実施するうえで、SEO対策は不可欠な施策となっています。
関連記事:SEO対策とは
LLMOをもっと勉強するには
LLMOをもっと勉強するには、書籍「
本書では、
・SEO・AIO・LLMO・GEO・AEOの整理と実務での考え方
・AIに理解され、信頼される情報設計の方法
・中小企業でも実行可能なLLMO戦略
・2026年を見据えたLLMO実践ロードマップ
といったテーマを網羅的に解説。短期的なテクニックや流行論ではなく、AI時代に企業が「どう認識され、どう選ばれるか」という本質に向き合った内容です。SEOの次を考えたい方、生成AI時代の検索・集客に不安を感じている方にとって、2026年以降のWEB戦略を考えるための“基本ガイド”となる一冊です。
まとめ
検索体験は、検索結果をクリックして情報を探す時代から、生成AIが答えそのものを提示する時代へと移行しています。こうした環境で重要になるのが、AIの回答内で自社やブランドが引用・推薦される状態をつくるLLMO(Large Language Model Optimization)です。
LLMOはSEOと対立する概念ではなく、SEOを土台として成立する最適化であり、検索エンジンに信頼されることがAIに選ばれる前提条件となります。実務では、実在性や専門性の明示、一次情報の提供、透明性の担保、エンティティ情報の一貫性、AIが引用しやすい文章構造、構造化データ、外部評価の蓄積やrobots.txtの整備が重要です。
効果測定では、AI回答内での認知を示すAI SOV、クリックなしでの影響を捉えるゼロクリック指標、行動や成果につながるAIリファラルを段階的に追い、定点観測と改善を続けることが、AI時代に選ばれる企業への近道となります。さらに、深く勉強したい方は、是非、書籍「




















