
canonicalタグとは?意味や重要なカノニカル設定について解説

検索エンジン最適化(SEO)において、ページの重複コンテンツは悪影響を与えることがあります。このような場合、同じコンテンツが複数のURLに存在するために、検索エンジンはどのページをインデックスして良いか判断できないからです。
この問題を解決するために、canonicalタグというものを使用します。
 そこでここでは、canonicalタグの意味や重要性、カノニカル設定方法などについてもお伝えします。
そこでここでは、canonicalタグの意味や重要性、カノニカル設定方法などについてもお伝えします。

canonicalタグとは?
canonicalとは検索エンジンにどのURLが本来のURLであるかを伝える手法のことです。例外を除き、ほとんどの場合では<hada>内のmetaタグで設定することができます。そのため、canonicalタグと呼ばれたり、単にカノニカルと呼ばれたりします。URLを1つに統一することでページの重複問題を解決できます。
WordPressで作ったサイトの場合には初期設定でcanonical設定が施されていることもありますので、いつの間にか終わっていたという人もいるようですが、SEO的には非常に重要な意味を持つタグですので必ず確認するようにしてください。
参考ページ:Canonical URLs: A Beginner’s Guide to Canonical Tags
本来のURLを伝えるとは?
URLの正規化に関わってきますが、重複する内容のページを作らないようにしていても以下のような重複ページができてしまうのはよくあることです。
http://sample-site.com/
https://sample-site.com/http://sample-site.com/index.html
https://sample-site.com/index.htmlhttp://www.sample-site.com/
https://www.sample-site.com/
これはどのようなサイトであっても起こりうることですので、通常はこの中から1つを自身の本当のURLとして設定をする必要があります。このように1つに統一することをURLの正規化といいます。
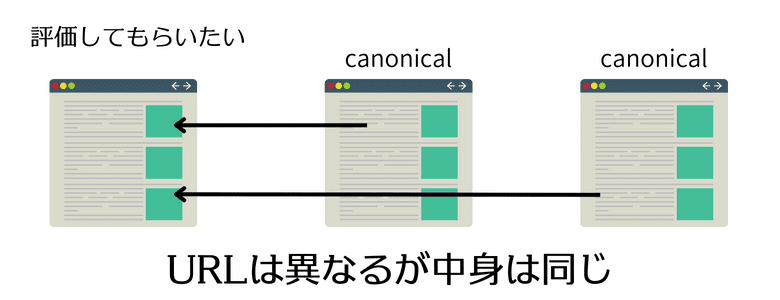
URLの正規化をしないとまったく同じ内容のページが複数存在することになってしまうので、評価が分散してしまい本来の評価を受けられなかったり、オリジナル性の低いページが複数あると判断されてしまうことになりかねません。
例えば、上記のURLの中で2番目の https://sample-site.com/ が正統とするならば、canonical設定は次のように行います。
<link rel=”canonical” href=”https://sample-site.com” />
リダイレクト(.htaccess)との違い
カノニカルの説明を聞いて、リダイレクトとは違うのか?と考えた人もいるはずです。重複コンテンツに対する施策という意味ではリダイレクトも同じように映りますが明確な違いがあります。
301リダイレクトではアクセスしてきたユーザーを強制的に設定したリンクに転送しますので強制力がありますが、カノニカルでは検索エンジンに対してヒントとなるシグナルを発信しているだけですので強制力はありません。
.htaccessでURLの正規化をすることでリダイレクトをすることはできますが、それだけでは対応できないときも多く、すべてのページでカノニカル設定をすることを推奨します。
rel=”alternate”タグの違い
canonicalタグとrel=”alternate”タグは、どちらも類似したタグですが機能は異なっています。
canonicalタグは、同じまたは類似したコンテンツが複数のURLに存在する場合に、どのURLが正式であるかを指定するために使います。
一方、rel=”alternate”タグは、同じコンテンツでも言語が異なっている別のバージョンであることを検索エンジンに伝えるためのものです。つまり、ユーザーが使用している言語にあわせたページを表示するために使用します。
canonical設定の重要性
同じまたは類似したコンテンツが複数のURLに存在する場合、カノニカル設定を使用することで、どのURLが正式であるかを指定することができます。
これにより検索エンジンは正しいページを認識することができ、適正な評価につながります。具体的には、以下のSEO効果があります。
- 重複ページの除外
- リンク評価の集約
カノニカル設定により、同じ内容のURLが複数あることで評価が分散されてしまうことを防ぐことができます。また、カノニカルをすることで対象ページにリンク評価を集めることもできます。
どちらもページ評価の際の重要な要素ですので必ず設定するようにしてください。
canonicalタグを使用しない場合のリスク
複数のWEBページが類似したコンテンツを持っているにもかかわらず、canonicalタグを使用しなかった場合、検索エンジンはどのページが最も重要であるかを判断することができません。
そのため、類似ページ同士が競合することになります。この競合によって、検索エンジンのランキングに悪影響が及ぶ可能性があります。
例えば、eコマースサイトで同じ製品を複数のページで販売しているとします。この場合、同じ商品の説明が複数のページに表示されます。すると検索エンジンは、どのページが最も重要であるかを判断することができません。
結果として、検索エンジンはそれぞれのページを別コンテンツとして扱うため、検索エンジンからの評価が分散します。
canonical設定すべき例
カノニカル設定はURLの正規化が正しくされていればやらなくてもよい施策ではあります。しかし、設定することのデメリットはなく、設定しないことのデメリットが大きいことからすべてのページで設定することを推奨しています。
中でも次の5つの場合には評価を分散させないためにも必ずおこなってください。
- 複数のURLがある場合
- 似た商品ページでURLが異なる場合
- パラメーター表示を使っている場合
- パソコンとモバイルでURLが異なる場合
- AMPに対応している場合
複数のURLがある場合
これは冒頭で述べた例です。同じサイトでもhttpとhttps、wwwのありなしでURLが存在している場合には.htaccessでのURLの正規化はもちろん、カノニカルもしておきます。
似た商品ページでURLが異なる場合
ECサイトによくある例ですが、同じ商品であってもサイズが違う、色が違うなどでURLが微妙に異なることがあります。この場合、コンテンツ自体は非常に似ていることが多く、重複ページと判断されないためにもカノニカル設定をすることをおすすめします。
パラメーターにも注意
上記のECサイトの例に近いのですが、ECサイトや大型サイトではURLにパラメーターを使っていることがあります。パラメーターの使い方次第ではありますが基本的にカノニカル設定をした方がよいことが多いです。
PCとモバイルでURLが違う場合
Googleはレスポンシブ対応を推奨していますが、レスポンシブ対応せずにパソコンとモバイルで別のURLを設定しているサイトもまだまだあります。基本的には同じコンテンツを配信しているはずですので片方にカノニカルすべきです。
AMPに対応している場合
AMP対応をしている場合、AMP用のHTMLでページを作らなければなりません。コンテンツは同一ではあるものの、重複ページになることがありますのでカノニカル設定をしてください。
この場合には通常ページにはAMPページがあることを明示し、AMPページにはオリジナルページがあることを明示する必要があります。
オリジナルページに追記
<link rel=”amphtml” href=”https://sample-site.com/amp/sample-page/” />
AMPページに追記
<link rel=”canonical” href=”https://sample-site.com/sample-page” />
canonical設定の確認方法
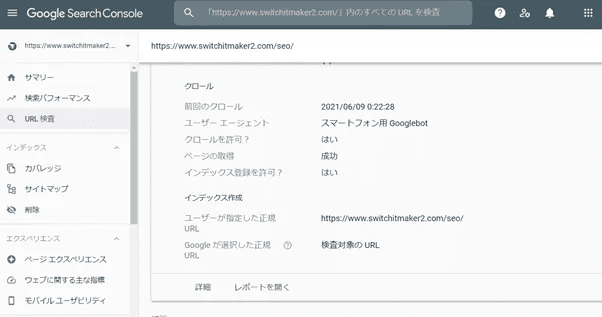
正しくカノニカル設定がされているかを確認する方法はいくつかありますが、もっとも確実な方法はGoogleサーチコンソールを使うことです。
左メニューのURL検査または上のバーにURLを入力すると上画像のように検査結果が出てきます。ここのインデックス作成欄にある「ユーザーが指定した正規URL」が自身が設定したものになっていれば問題ありません。
その下にある「Googleが選択した正規URL」が自身の設定と異なる場合にはカノニカル設定がされていないか、設定されていても何かしらの原因で別ページが正規URLとして認識されてしまっている状態です。
canonicalでよくある間違い
Googleウェブマスター向け公式ブログの「rel=canonical 属性に関する 5 つのよくある間違い」の記事でカノニカル設定をする際によくある間違いについてGoogleがまとめています。 2013年の記事ではありますが、現在でも通用する内容ですのでご一読ください。
複数ページの1ページ目をcanonicalにしてしまう
ニュースサイトなどでよく見かけますが、1ページが長くなってしまうため1つの記事を2ページ、3ページに分けることがあります。1記事を分けることは問題ありませんが、その際にすべてのページを1ページ目にカノニカルするのは問題です。2ページ目の内容と1ページ目は明らかに別の内容が入っているからです。
相対URLを記載してしまう
URLの表記方法には絶対URLと相対URLがあります。
- 絶対URL:https://www.switchitmaker2.com/wordpress/seo/
- 相対URL:/seo/
見てお分かりの通り、絶対URLはすべてを記載したURLで相対URLはドメイン部分を省いたURLです。相対URLでは反映されませんのでご注意ください。
2つ以上設定してしまう
設定の誤りでカノニカル設定を2つ入れてしまうと正しく機能しません。通常は2つ以上の設定がされることはありませんが、単にHTMLの記述ミスやプラグインを複数入れたことによる重複などが考えられます。
カテゴリページから特集ページにcanonicalしてしまう
これはGoogleが指摘している例です。カテゴリページで特集記事を紹介していて、その内容が似ているので特集ページをカノニカルするという例です。これを施すとカテゴリページはインデックスされないことが起こりますのでやめてください。
<body>タグ内に入れてしまう
カノニカルタグは<head>タグの中で効果を発揮するタグです。それ以外の場所に入れても無効になりますので気を付けてください。
canonical設定時の注意点
カノニカル設定を間違えると検索結果に出てこなくなることもある、SEO観点では非常に重要なタグです。そのため、次の点には必ず注意してください。
すべてのページに設定する
厳密にはすべてのページにカノニカルをしなくても問題ありません。しかし、するページ、しないページを作ることで混乱を招くこと、すべきページでできているかを確認しづらくなることからすべてのページで設定することを推奨します。
WordPressなどのCMSで作っているページであればかなり簡単に設定できるはずです。
すべてのURLを同じにしてはいけない
極まれに発生するSEOあるあるなのですが、評価やリンクを集めるためにすべてのページのカノニカルをトップページにしてしまうという例があります。これは大きな誤りですので絶対にやめてください。
すべてのURLを同じにするとそのサイトの中には1ページしか存在しないように見えますし、コンテンツもページごとに異なるので正しい設定ではありません。結果的にはマイナスになることがほとんどです。
設定を誤ると検索結果に出てこなくなる
これはほとんどありませんが、設定を誤ると検索結果にページが出なくなることがあります。設定で存在しないページを指定した場合などに起こりえます。
ただし、Googleの精度は非常に高く、存在しない場合には存在するページを検索結果に出すということがほとんどです。リダイレクトのような命令とは違い、カノニカルは検索エンジンに対するシグナルにすぎないからです。
リンク先が存在するかどうか
カノニカルで設定するリンク先が存在するかどうかは重要なチェックポイントです。存在しない場合でも存在するページをインデックスするのがGoogleですが確実とは言い切れません。コピペミスなどで存在しないページを指定してしまうと後々面倒なことになります。
リンク先にnoindexがない
カノニカルで設定したページにnoindexがあった場合、検索エンジンは混乱することになります。こちらが正規URLだと指定しておきながら、正規URLを見るとインデックスしないでくれと言っているからです。noindexを設定している限り検索結果に表示されない可能性があります。
※noindexの設定方法としては正しいです。管理者の意図でこのようになっている場合には問題ありません。
日本語URLを使わない
ピュニコードというものを聞いたことがあるでしょうか?日本語URLを文字列に変換したものといえばわかりやすいかもしれません。
例えば、次のようなURLがあったとします。
https://sample-site.com/検索順位を上げる方法/
これは日本語を使った正しいURLではありますが、コンピュータが理解が難しく、カノニカル設定をする時にはピュニコードに書き換える必要があります。
ニュース記事とcanonical問題
ここまででSEOにおけるカノニカルについて触れてきましたが、ニュースサイトなどではこのカノニカルが問題になっています。というよりも、WEBサイトの取り扱いという点では大きな問題になるはずなのですが、目を瞑っているサイトが多く、問題意識さえない人もいるように思えます。
カノニカル設定を正しく使うことで本来の正しいURLを検索エンジンに伝えることができます。このおかげでコピーコンテンツがあったとしても、設定されていればオリジナルサイトが不利益を被ることはありません(とはいえ、コピーすることそのものが非推奨です)。
しかし、大手ニュースサイトでも多メディアの記事を紹介するものの、カノニカルでリンク先は渡さないということが往々にしてあります。
Google ニュースでの記事の重複を避ける方法
Googleもこの問題は認識しているようで、Googleニュースでの記事の重複を避ける でカノニカル設定をするように推奨しています。
しかし、さすがに他のニュースサイトにまでは言及できないようです。
こんな中、新R25というサイトではカノニカル設定をオリジナルサイトに設定するという英断をしています。2018年のことですので少し古い情報になりますが、ニュースサイトのカノニカル問題は現在でも続いている問題です。これは非常に画期的な試みですので今後はこのようなサイトが広まってくれることが切に望まれます。
新R25
https://r25.jp/
「新R25」は、これからの時代を生きるR25世代(20~30代)のビジネスパーソンに向けて、人生を豊かにする情報や考え方を“おもしろく”届け、一歩を踏み出すキッカケづくりをサポ―トするWEBメディア
canonicalタグのよくある質問
ここでは、canonicalタグについて寄せられる質問の中から、代表的なものを取り上げ解説します。
Q:どのような場合にcanonicalタグは使用されますか?
Answer)canonicalタグは、同じまたは類似したコンテンツが複数のURLに存在する場合に使用します。複数のページが同じコンテンツを持っている場合、検索エンジンに対してどのページが正式なバージョンであるかを伝えるためです。
Q: canonicalタグの使用で、SEOに効果はありますか?
Answer)canonicalタグを使用することは、検索エンジンから適切な評価をえるうえで大切です。仮に重複したコンテンツが残ったままだと評価分散が起こり、SEOにおいても不利に働きます。
Q: SEO効果はすぐに現れますか?
Answer)canonicalタグの設定による効果はすぐに現れるとは限りません。検索エンジンは、新しい情報を収集してインデックスするまでに相応の時間がかかります。
Q:タグを設定するページの数に上限はありますか?
Answer)canonicalタグを設定する必要があるページの数に上限はありません。同じまたは類似したコンテンツが複数のURLに存在する場合、どのURLが正式であるかを指定するために、そのページ数分のcanonicalタグを設定することができます。
まとめ
カノニカル設定1つとってみても技術的に気を付けなければいけないことが多くあります。よく勉強してミスなくカノニカル設定をしてください。Google search consoleで必ずカノニカル設定が問題なくできているか確認することも大切です。どうしてもうまくできない時は専門家に相談してください。

この記事の監修者

日本大学法学部卒業、広告代理店で12年間働いている間、SEOと出会い、SEO草創期からSEO研究を始める。SEOを独学で研究し100以上のサイトで実験と検証を繰り返しました。そのノウハウを元に起業し現在、10期目。営業、SEOコンサル、WEB解析(Googleアナリティクス個人認定資格GAIQ保持)コーディング、サイト制作となんでもこなす。会社としては今まで2000以上のサイトのSEO対策を手掛けてきました。
















